

Jupyter 是一个基于 Web 的交互式计算平台,使用户能够创建和共享文档,这些文档包含实时代码、方程式、可视化图表和解释文字。Jupyter 在数据分析领域被广泛应用,它提供了一个直观、交互式的操作界面,使得用户能够更容易地探索数据、可视化数据以及进行数据处理和建模的实验。
Jupyter 不仅能够对 Python 代码进行展示和格式化,还能够保存用户的历史代码和结果以及数据分析结果。这些结果可以在后期随时查看和修改,使得 Python 的学习和应用变得更加方便和高效。
总之,学习一下jupyter还是非常必要的,也非常的方便,本文的操作主要针对Windows系统。
1.安装Jupyter
安装是非常简单的,一般有两种方式,一种就是python环境,另外一种就是Anaconda环境;
1.1Python 环境下安装
-
安装 Python。从 Python 官方网站[1]下载最新版本的 Python。
-
安装 pip。pip 是 Python 的包管理工具,用于安装和管理 Python 包。在命令行输入以下命令来检查 pip 是否已经安装:
pip --version如果 pip 已经安装则会输出 pip 的版本信息,否则需要手动安装。
-
安装 Jupyter Notebook。使用 pip 命令来安装 Jupyter Notebook。在命令提示符或终端窗口中输入以下命令:
pip install jupyter等待一段时间,Jupyter Notebook 就会被安装到你的电脑上了。
-
启动 Jupyter Notebook。安装完成后,在命令提示符或终端窗口中输入以下命令来启动 Jupyter Notebook :
jupyter notebook这个命令会自动打开你的默认浏览器,展示 Jupyter Notebook 的主页,并在后台启动一个 Jupyter 内核(Kernel)。
1.2Anaconda 环境下安装
正常的话,安装Anaconda的时候,jupyter是伴随anaconda安装好的,不需要按照如下步骤再去安装;
-
安装 Anaconda。从 Anaconda 官方网站[3]下载最新版本的 Anaconda。
-
启动 Anaconda Navigator。安装完毕后,启动 Anaconda Navigator,它是一个可视化的应用程序,方便用户管理和运行 Anaconda 中包含的各种工具和应用。
-
安装 Jupyter Notebook。在 Anaconda Navigator 中,点击左侧导航栏的 “Environments”,然后在右边的区域中选中需要安装 Jupyter Notebook 的环境,在下方的 “Packages” 标签页中搜索 “jupyter”,并勾选 “jupyter” 和 “notebook”。然后点击 “Apply” 按钮进行安装即可。

-
启动 Jupyter Notebook。安装完成后,在 Anaconda Navigator 中点击 “Launch” 按钮启动 Jupyter Notebook,也可以在命令提示符或终端窗口中输入以下命令来启动:
jupyter notebook
2.启动命令
-
默认端口启动
jupyter notebook浏览器地址栏中默认地将会显示:http://localhost:8888/tree。其中,“localhost”指的是本机,“8888”则是端口号,每多启动一次,端口号类推
-
指定端口启动
jupyter notebook --port <port_number> 指定端口号只有数字,不含 <> -
启动服务器但不打开浏览器
jupyter notebook --no-browser终端会显示出打开浏览器的链接,若需启动浏览器,复制链接打开即可
3.配置文件存放位置
Jupyter Notebook 的启动目录是指 Jupyter Notebook 执行服务时的默认工作目录。当你在 Jupyter Notebook 中新建一个文件时,默认情况下会在该目录下创建文件。
设置 Jupyter Notebook 的启动目录非常有用,尤其是在你的工程有大量分散在不同目录中的数据或代码时。通过将启动目录设置为你的工程根目录,你就可以更轻松的管理和访问这些数据或代码了。
例如,假设你有一个名为 “my_project” 的项目,其中包含多个子目录和数据文件。如果你将 Jupyter Notebook 的启动目录设置为 “my_project” 目录,那么你就可以很方便地访问这个项目中的任何文件,而无需在 Jupyter Notebook 中输入完整路径。
另外,在 Jupyter Notebook 里,你可以使用一些 Python 库来处理和可视化你的数据。如果你使用的是相对路径来访问数据文件,那么使用相对于启动目录的路径通常会比使用绝对路径更方便。
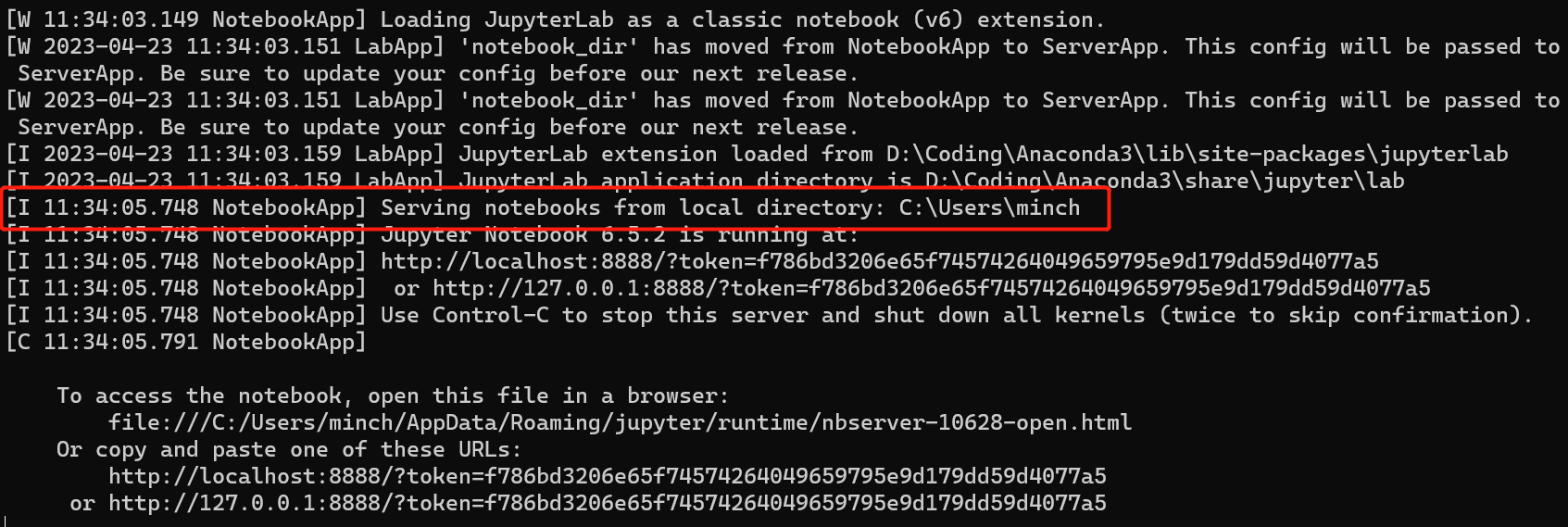
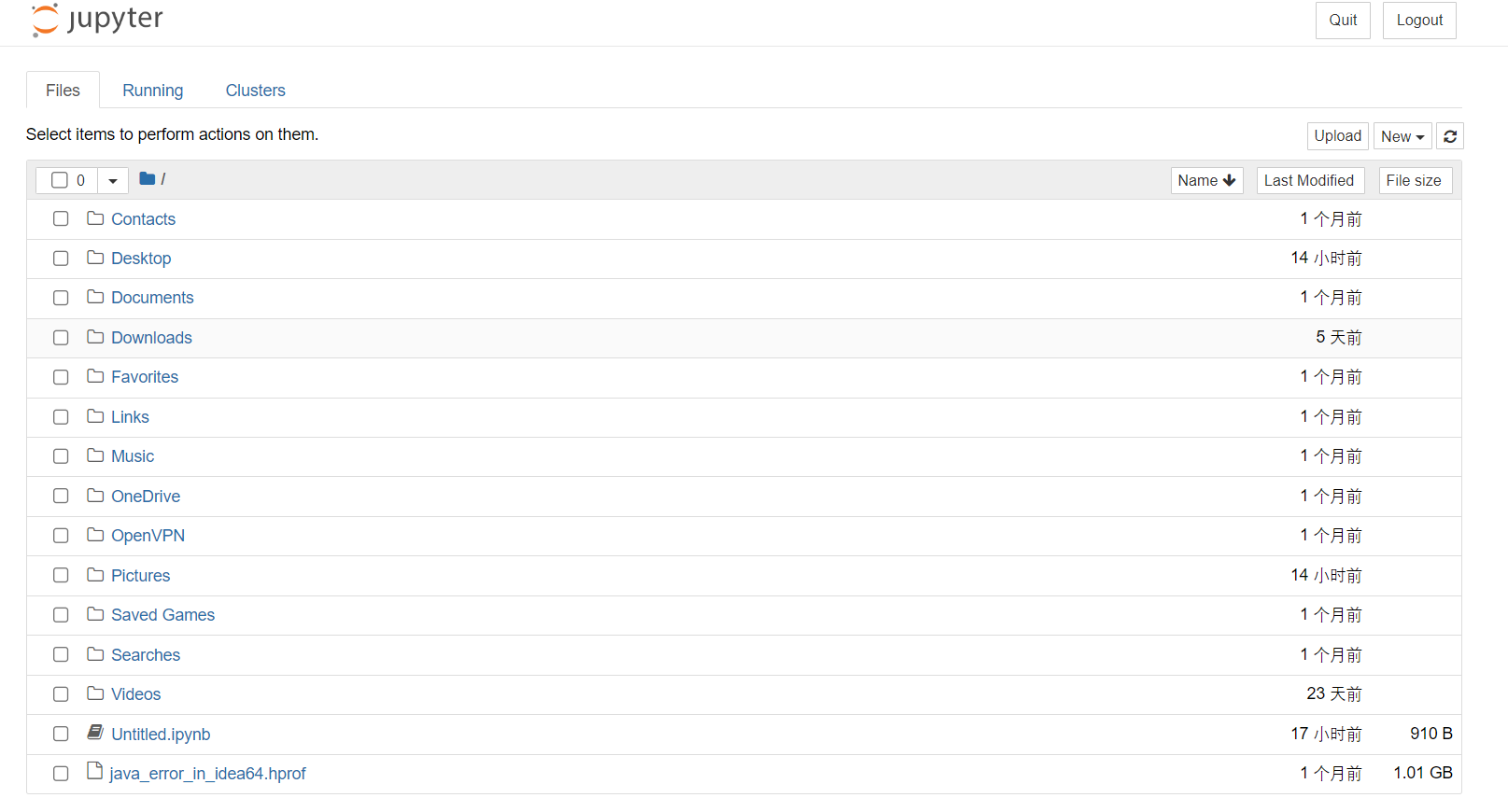
jupyter默认文件都放在用户目录下,如下图,启动的时候就可以看到启动目录;进入jupyter也确实是这个目录下的内容;显然这是有问题的,所以需要我们更改文件的存放位置;
-
新建一个目标文件夹
在你想放这些文件的位置新建一个目录,比如我的目录是:
D:\Coding\Jupyter_PyProject -
查看配置文件路径
命令窗口输入这行命令,或者在你对应的python环境下的命令窗口输入这行命令,即可查看默认的配置文件位置;但是这条命令虽然可以用于查看配置文件所在的路径,但主要用途是是否将这个路径下的配置文件替换为默认配置文件(相当于重置)
jupyter notebook --generate-config
-
修改配置文件
上面找到了配置文件的位置,现在我们只需要打开这个文件,然后编辑即可;windows比较方便,利用记事本打开可以打开,但是可能找目标代码就有点麻烦了,这里使用notepad++打开;直接Ctrl+F搜索关键字
c.NotebookApp.notebook_dir,就可以找到目标代码行了;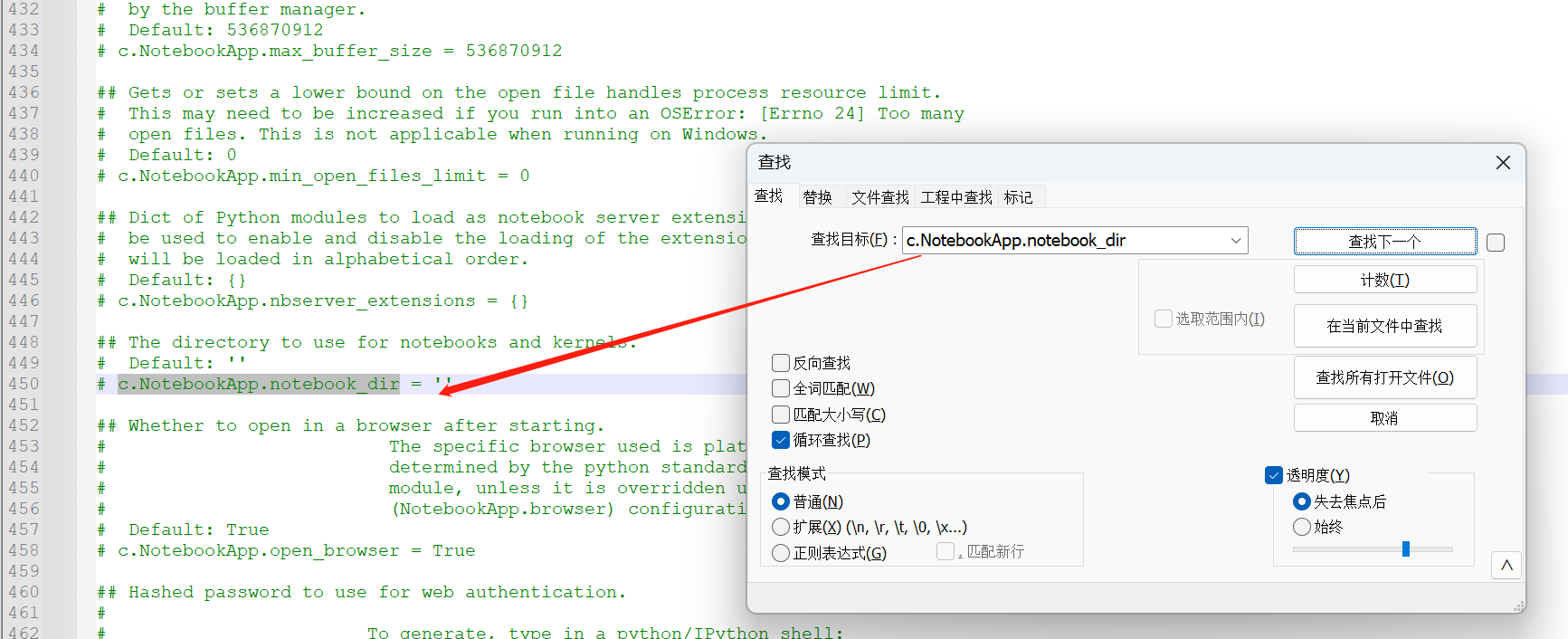
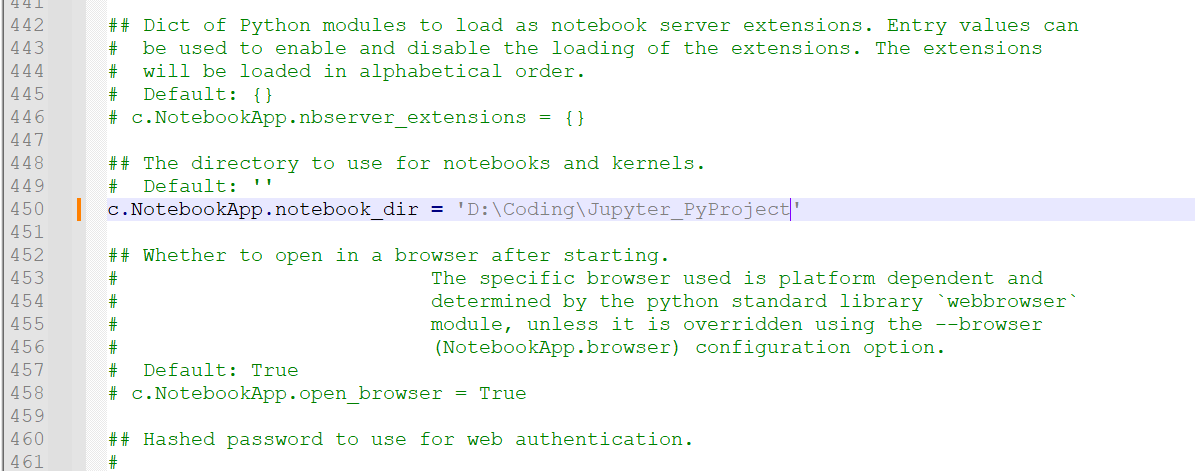
找到这行代码后,取消注释,并在单引号内写上事先建好的用来存放文件的目录地址,保存退出;
-
重新启动jupyter验证配置情况;
可以看到这里已经修改成功了;
-
这里有个坑
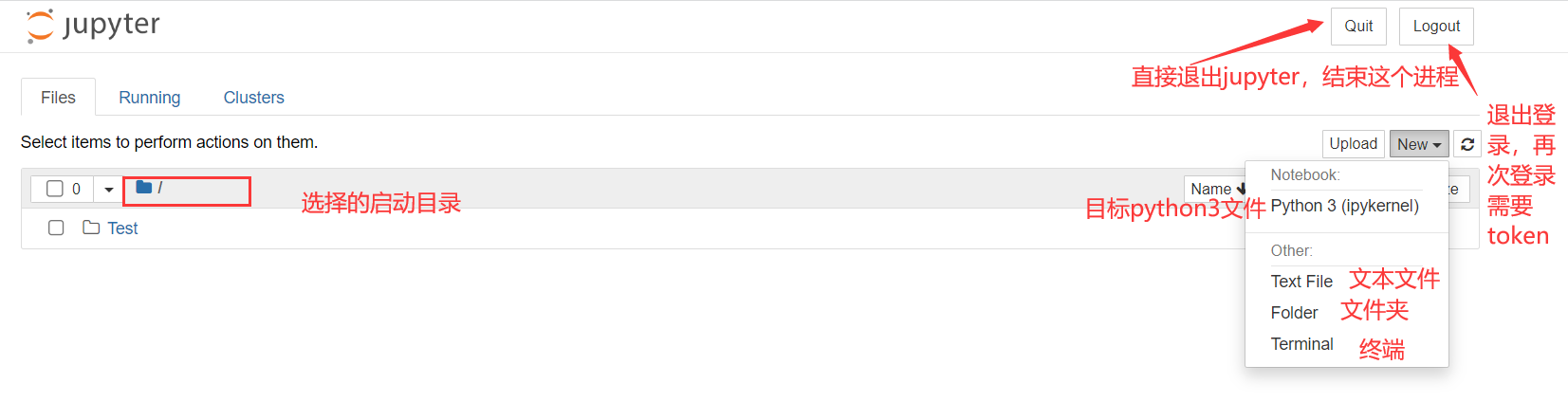
这里要强调一下通过命令打开和通过anaconda安装的时候提供的快捷方式打开,因为这里有坑,当你安装完Anaconda的时候,你会发现利用命令和快捷方式都能打开一个jupyter,这俩打开方式是不一样的,比如修改好了jupyter的启动目录,但是在使用快捷方式打开后,启动目录还是默认的目录;具体的差别请查看下面的Q&A部分;
4.界面功能
-
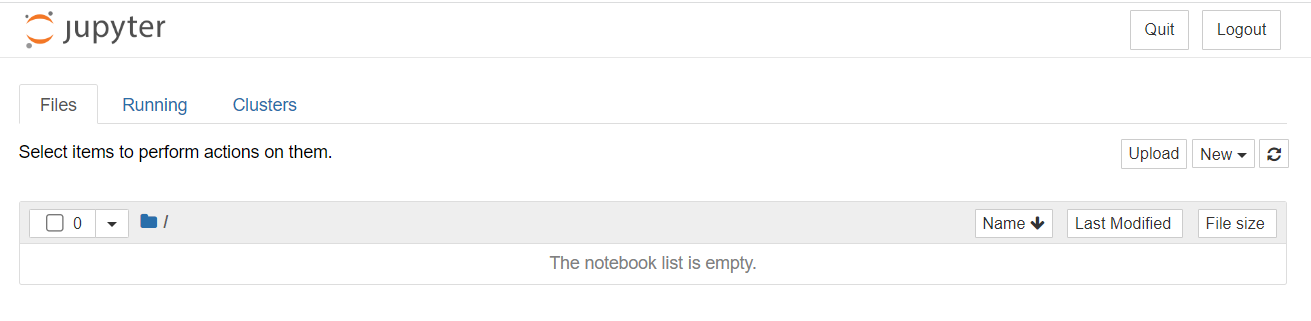
Files
-
Running
Running tab 显示了当前正在运行的内核和 Jupyter Notebook 进程。具体来说,Running tab 会列出所有当前正在运行的 Notebook,包括它的名称、所在目录、 Noteboook 文件的路径、内核(kernel)的状态、连接的用户以及它的启动时间等信息。
通过 Running tab,您可以方便地查看已经打开的 Notebook,并可以选择以不同的方式关闭它们(关闭 Notebook 不会关闭内核),如停止内核、重启内核、删除 Notebook、打开终端、查看 Notebook 的启动日志等。此外,Running tab 还提供了一些高级功能,如将多个 Notebook 捆绑到单个服务中、配置和管理 Jupyter Notebook 服务器等。

-
Clusters
在 Jupyter Notebook 中,Clusters tab 是指 Jupyter notebook 的一个组件,它是 IPython parallel 包提供的一个交互式界面,用于在多台计算机之间分配任务和协调计算。具体来说,Clusters tab 允许用户连接到一个或多个远程 IPython 核心(IPython engines),并在这些核心之间分发计算任务。
在 Clusters tab 中,用户可以通过添加、删除、启动、停止和连接到 IPython 集群来管理集群。一旦连接到集群,用户可以在各个核心之间分配计算任务,以便以最大程度地同时使用多台计算机的 CPU 和内存资源。Clusters tab 还提供了一些额外的功能,如查看集群状态、监控工作负载和任务进度等。
一般不用…
-
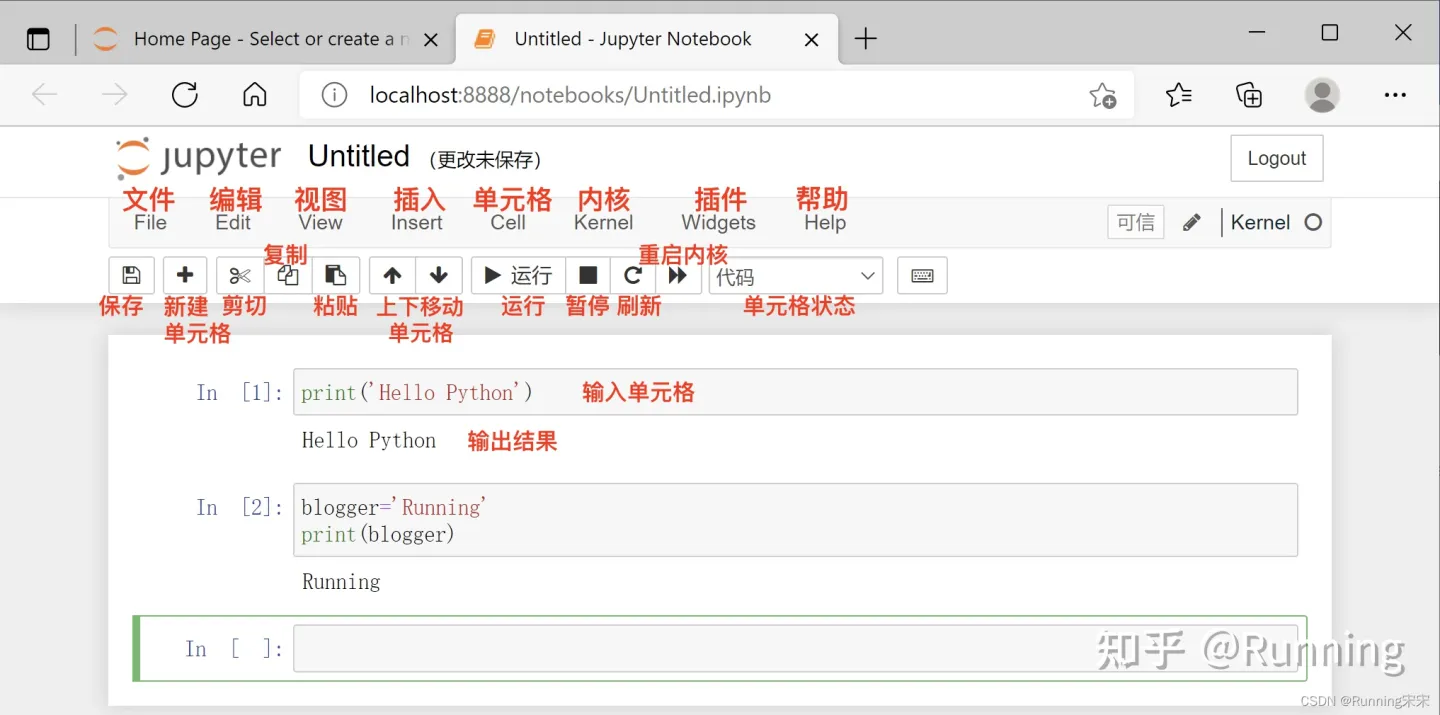
编辑器界面
这里搬运一张其他博主的图片,原文:https://zhuanlan.zhihu.com/p/441668517
其实还是比较清晰的,但是如果你还是不熟悉,就翻译呗,翻译网页就ok了,至于汉化,网上很多办法反正我都没成功。
5.主题扩展
5.1配置方法
-
安装
利用pip安装主题扩展
pip install jupyterthemes -
加载可用的主题列表
jt -l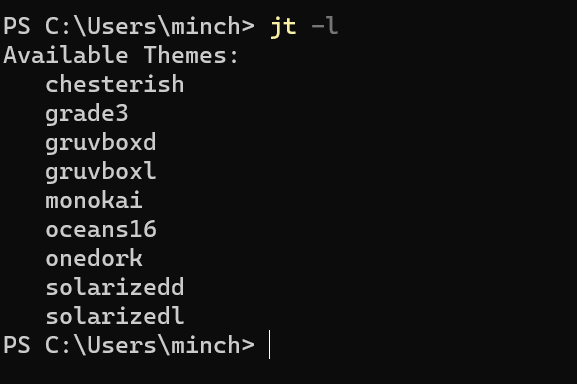
-
应用某个主题
这里的主题名称就是上面主题列表中的主题名,如果命令报错,看下面的解决办法;
jt -t 主题名称 -
高级的配置
jt -t 主题名称 -f 字体名称 -fs 字体大小 -cellw 代码单元格宽度 -T 工具栏 -N 笔记本名称 -
还原默认主题
jt -r -
jt命令不可用解决办法
安装jupyter themes之后,运行jt命令,报错如下
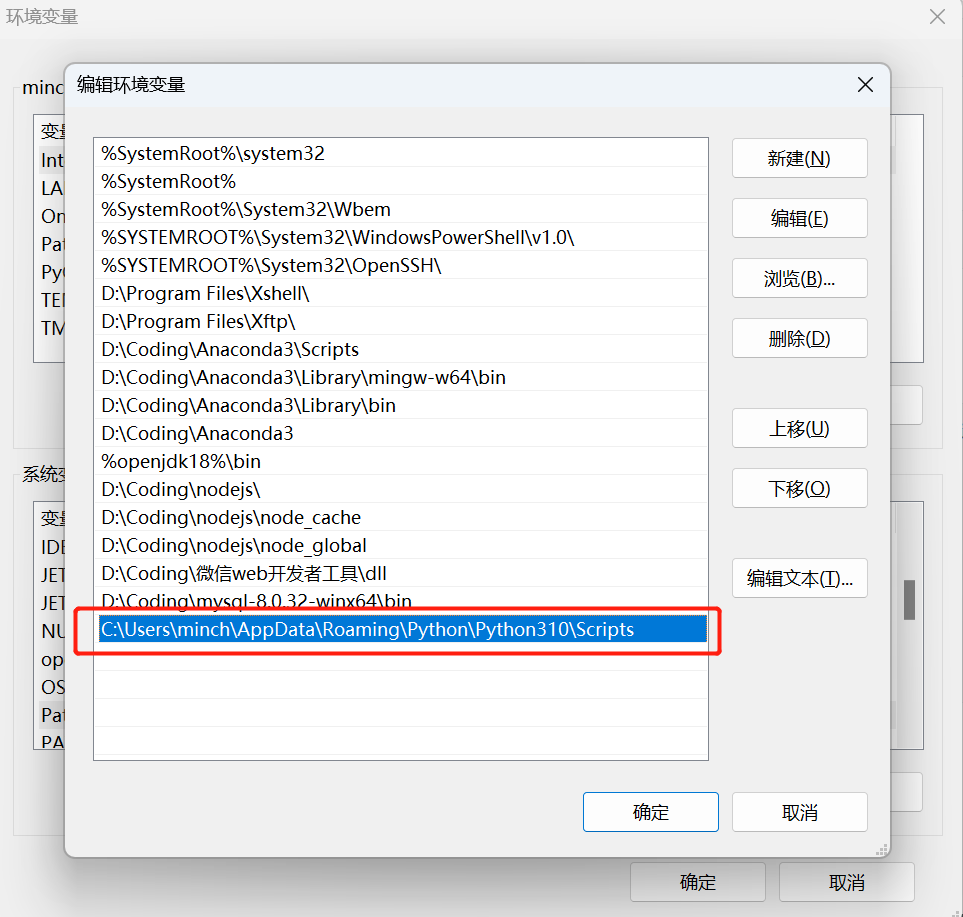
jt : 无法将“jt”项识别为 cmdlet、函数、脚本文件或可运行程序的名称。请检查名称的拼写,如果包括路径,请确保路径正确,然后再 试一次。 所在位置 行:1 字符: 1 + jt -l + ~~ + CategoryInfo : ObjectNotFound: (jt:String) [], CommandNotFoundException + FullyQualifiedErrorId : CommandNotFoundException解决办法就是配置一下环境变量,打开环境变量——点击系统变量——点击PATH——新建;
当然这里的路径要和你的本地环境一致;
如果不知道路径的话,可以打开命令窗口;切换到你安装
jupyter themes的环境下(你没有安装多个虚拟环境,或者你jupyter就安装在默认的环境下,就不用管),运行pip show jupyterthemes;最后不要定位到
site-packages目录,要定位到Scripts目录;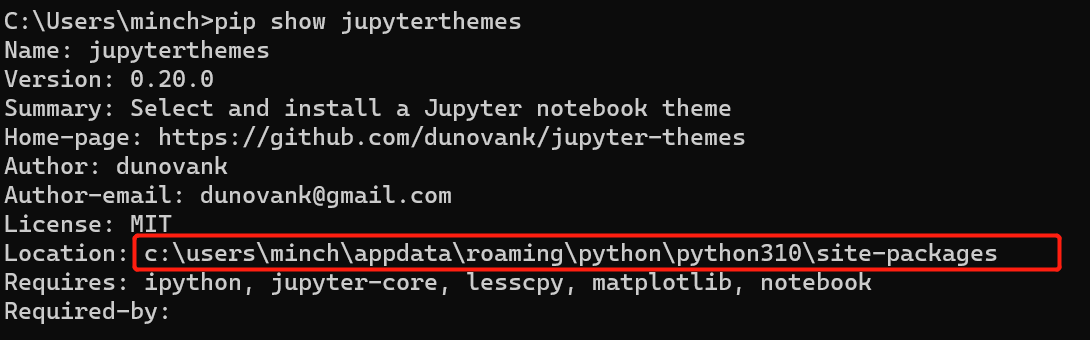
5.2主题一览
-
chesterish
-
grade3
-
gruvboxd
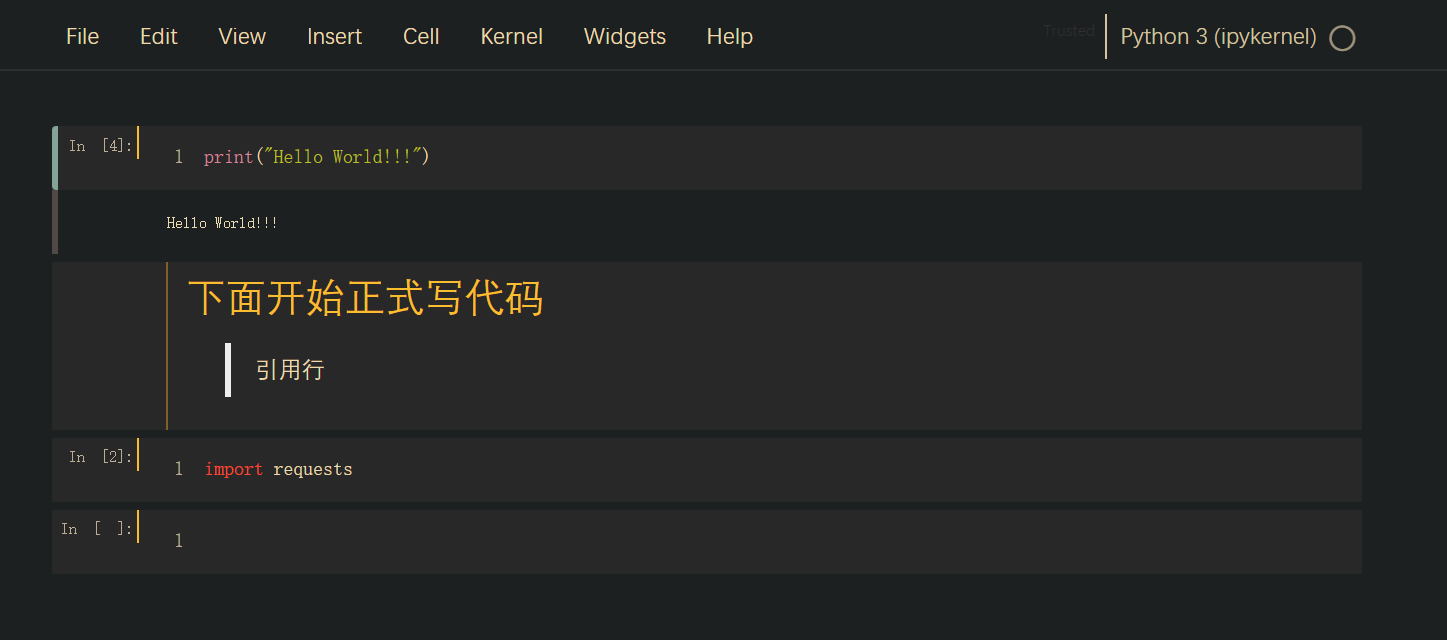
-
gruvboxl
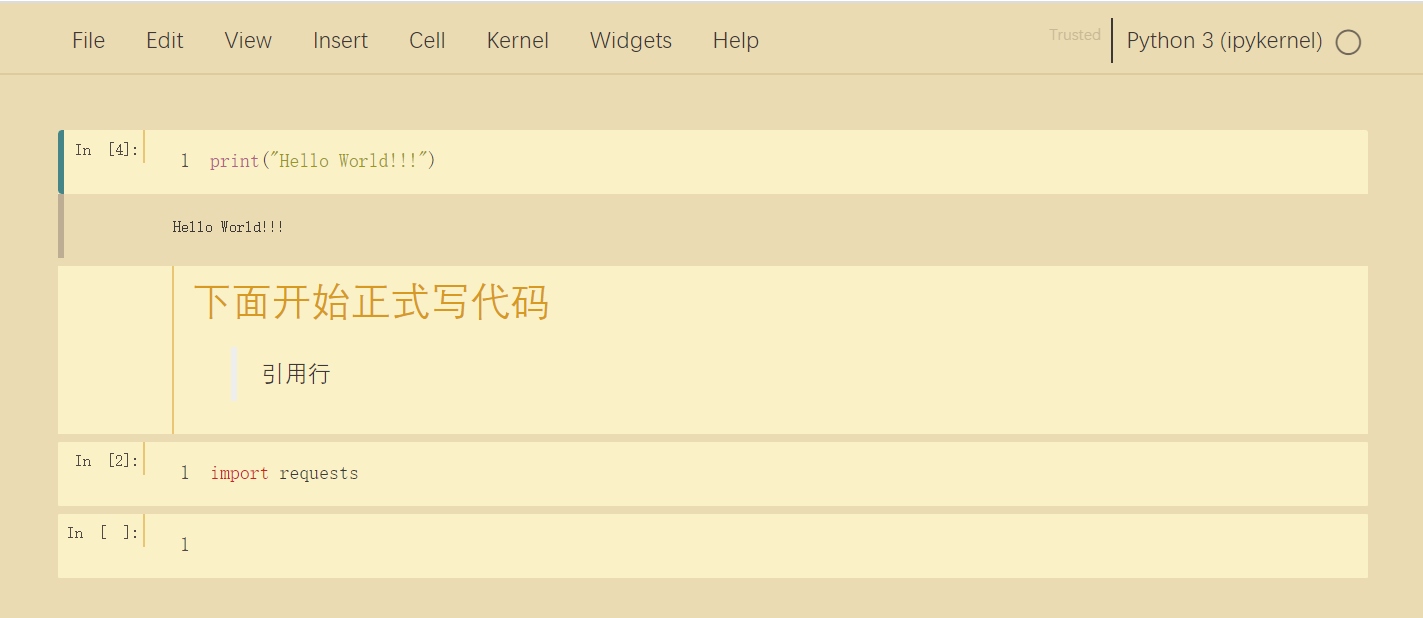
-
monokai
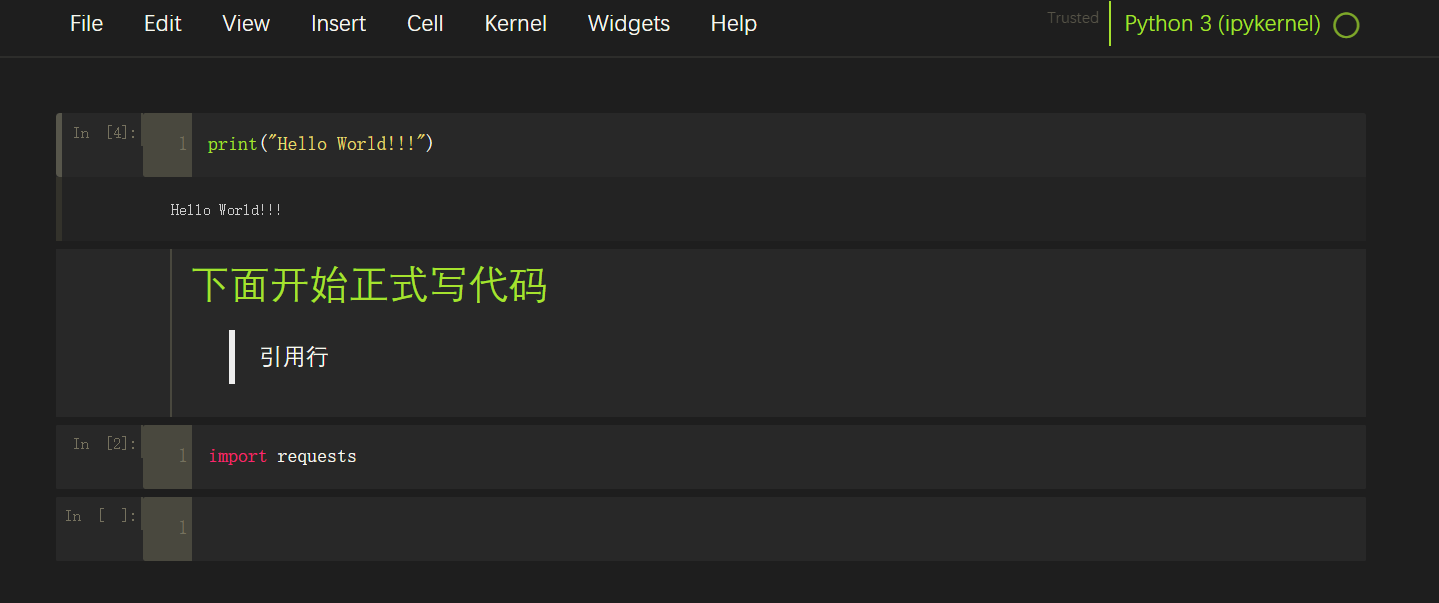
-
oceans16
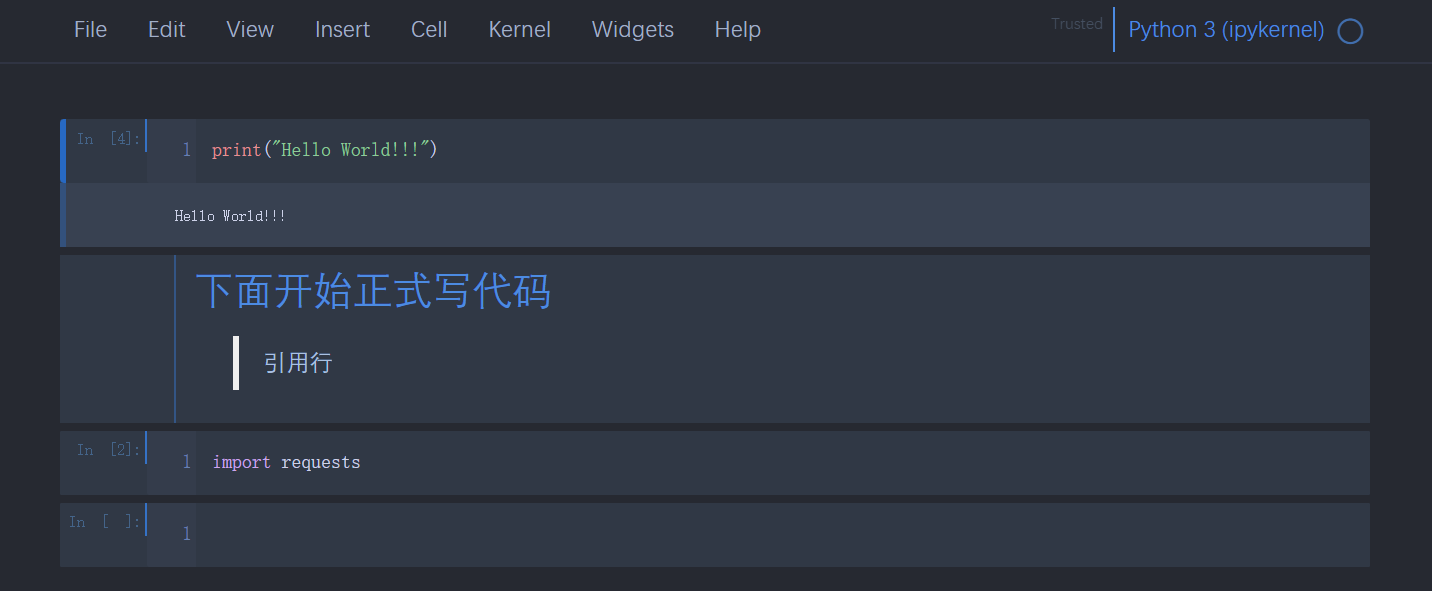
-
onedork
-
solarizedd
-
solarizedl
6功能扩展
6.1关联Anaconda环境
6.1.1简介与安装
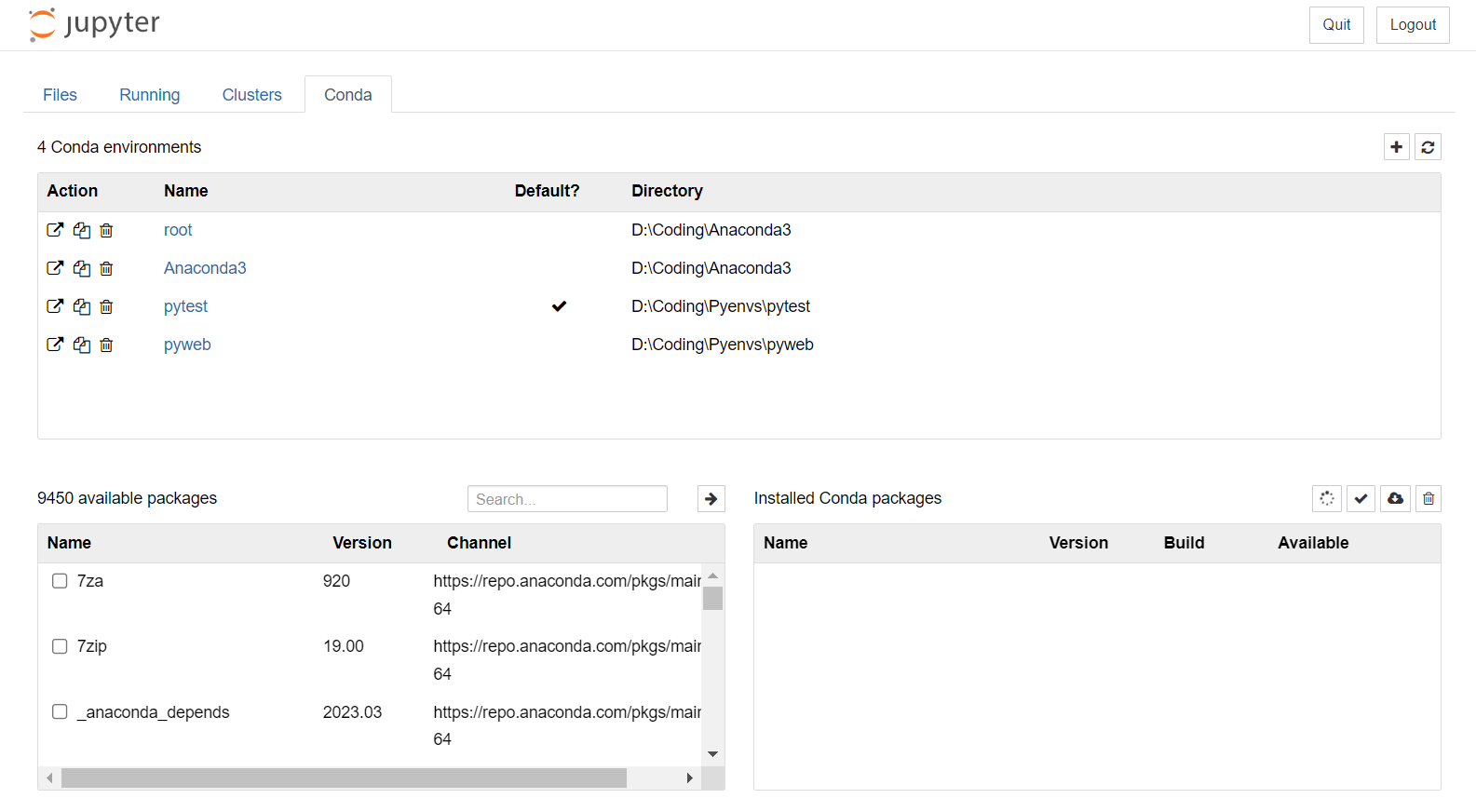
nb_conda是一个 Jupyter Notebook 的插件,它可以在 Notebook 中实现 Conda 环境和包的访问。在 Jupyter 的文件浏览器中,nb_conda扩展会添加一个 Conda 选项卡,点击该选项卡即可查看已存在的 Conda 环境列表。通过nb_conda,用户可以轻松地在 Notebook 中创建、使用和分享自己的 Conda 环境。
-
安装
conda install nb_conda -
卸载
canda remove nb_conda
6.1.2使用简介
-
选择conda导航栏,就能显示anaconda的环境和包了;
-
Kernel选择
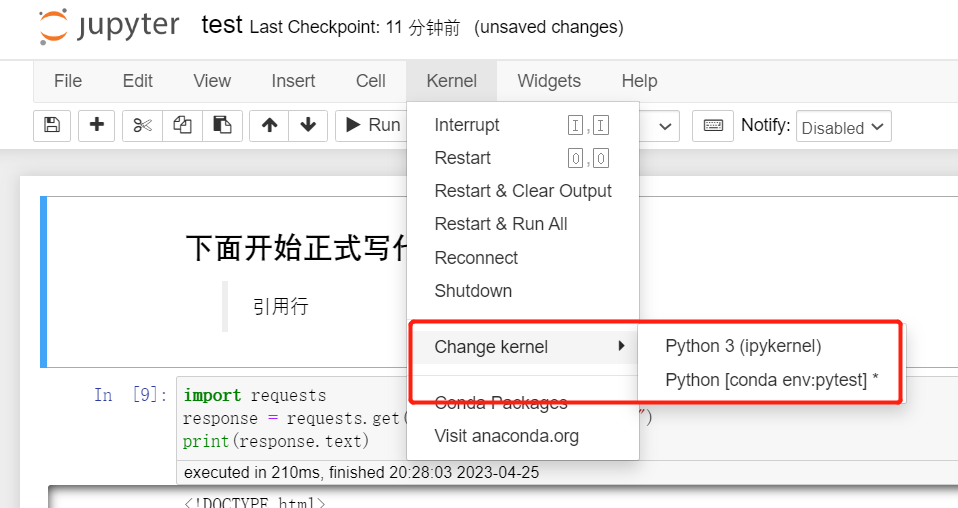
6.2扩展库
6.2.1简介与安装
扩展库一般涉及两个东西,一个就是
jupyter_nbextensions_configurator,另一个是jupyter_contrib_nbextensions;
jupyter_nbextensions_configurator是一个用于管理和配置 Jupyter Notebook 的笔记本扩展程序的 GUI 工具。它提供了图形用户界面(GUI)来启用、禁用和配置 Jupyter Notebook 的 nbextensions 扩展程序。它还允许你使用预定义选项来配置这些扩展程序,使其更加符合你的需求。此外,它还提供了一些主题以改变笔记本的样式和交互体验。
jupyter_contrib_nbextensions则是一组可用于增强 Jupyter Notebooks 功能的扩展程序集合。这些扩展包含多种类型的实用工具,如代码折叠、高亮显示、表格排序、导航栏等等。通过安装 jupyter_contrib_nbextensions,你可以更方便地管理你的笔记本,提高编程效率。需要注意的是,jupyter_contrib_nbextensions 中包括了 nbextensions_configurator 工具。
-
pip安装
pip install jupyter_contrib_nbextensions jupyter contrib nbextensions install --user pip install jupyter_nbextensions_configurator jupyter nbextensions_configurator enable --user -
conda安装
conda install -c conda-forge jupyter_contrib_nbextensions jupyter contrib nbextension install --user conda install -c conda-forge jupyter_nbextensions_configurator jupyter nbextensions_configurator enable --user -
安装后发现扩展库里面只有四五个
把扩展库卸载了重新装一遍就行了,建议一行一行的跑命令;
-
pip卸载
pip uninstall jupyter_contrib_nbextensions -
anaconda卸载
conda remove jupyter_nbextensions_configurator
-
-
安装之后,启动jupyter就能看到nbextensions了,要取消图中的选择,才能使用;使用即在对应的扩展前面选中即可;
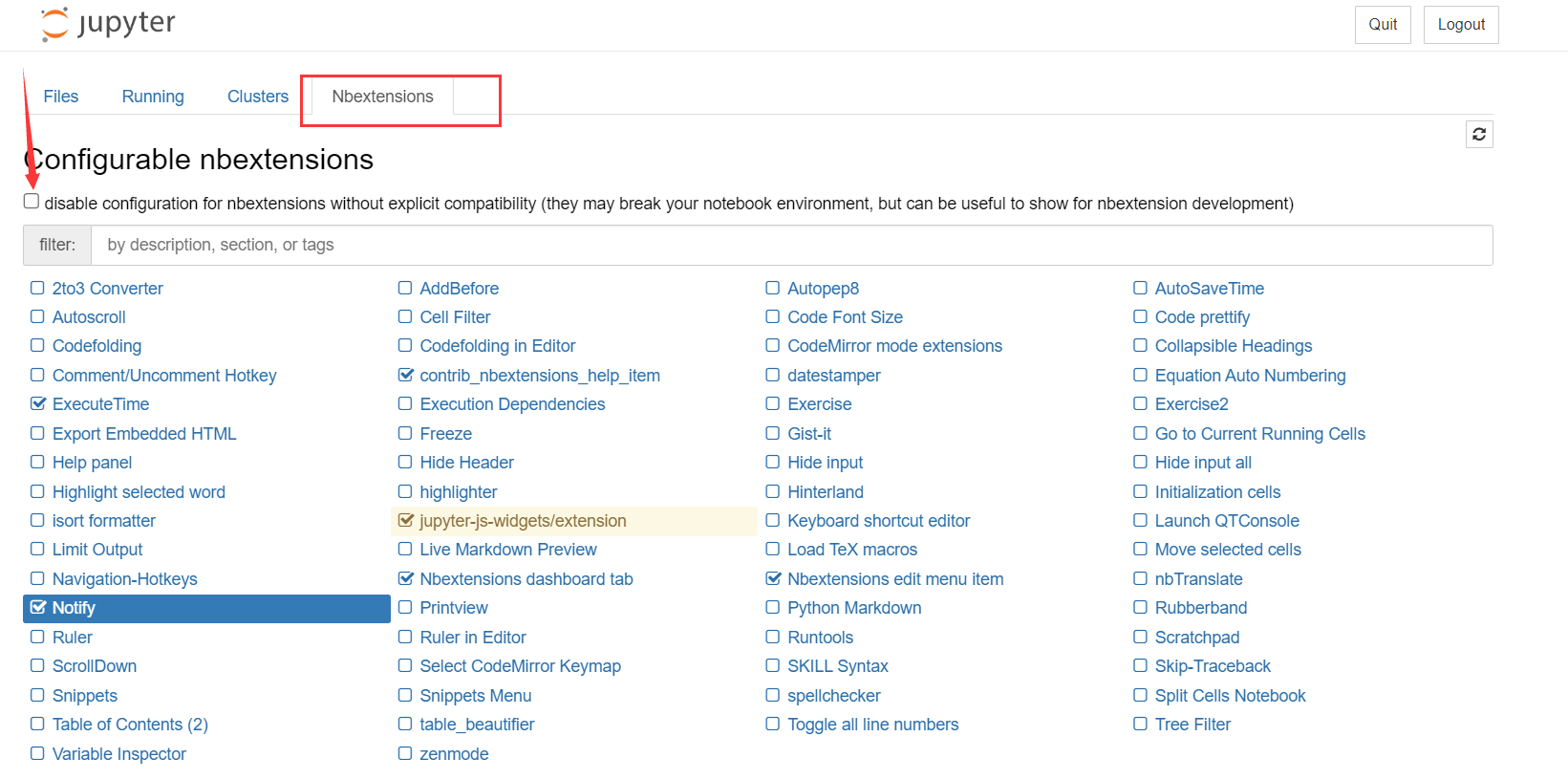
6.2.1扩展推荐
-
Table of Contents: 自动生成文档中的目录,方便快速导航和查找内容。[1]
-
Collapsible Headings: 折叠和展开单元格标题,节省页面空间并使整个文档更易于导航。[2] -
Code Folding: 可以折叠代码单元格中的代码块,有助于隐藏不必要的细节并提高可读性。 [3] -
ExecuteTime: 显示代码单元格的执行时间。[4]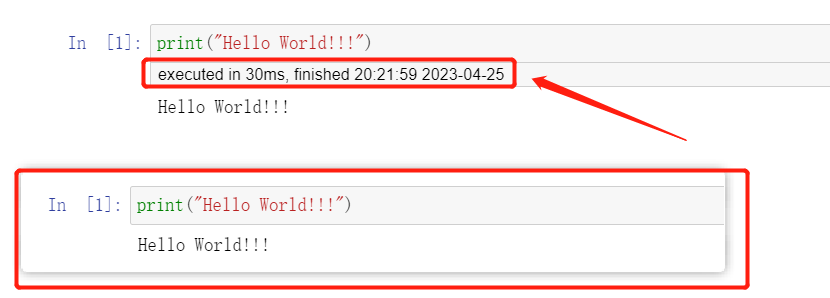
-
Notify: 当代码执行完成时向浏览器推送通知。[5]
部分内容及图片来源:https://cloud.tencent.com/developer/article/2135662
7.基本使用
先摆上两个链接,更多详细的内容参看:
-
Jupyter Notebook笔记本的两种模式
-
命令模式
命令模式将键盘命令与Jupyter Notebook笔记本命令相结合,可以通过键盘不同键的组合运行笔记本的命令。
按esc键进入命令模式。
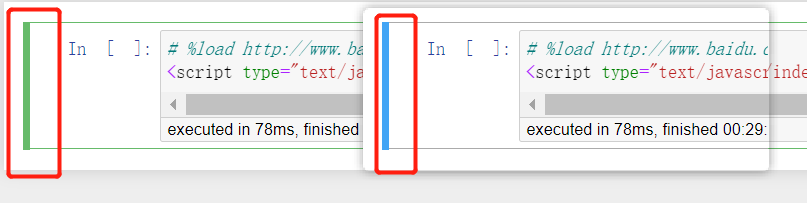
命令模式下,左侧边框线为蓝色粗线条。 -
编辑模式
编辑模式使用户可以在单元格内编辑代码或文档。
编辑模式下,单元格边框和左侧边框线均为绿色。
-
-
删除单元格快捷方式:进入命令模式后双击D键
-
恢复单元格:进入命令模式后按Z键
-
Shift-Enter : 运行本单元,选中下个单元
-
Ctrl-Enter : 运行本单元
-
Alt-Enter : 运行本单元,在其下插入新单元
-
加载指定位置源代码
想要在Jupyter Notebook中直接加载指定位置的源代码到笔记本中;
输入以下命令运行即可加载,运行完之后,代码会加载到单元格内,该命令会被注释;
%load URL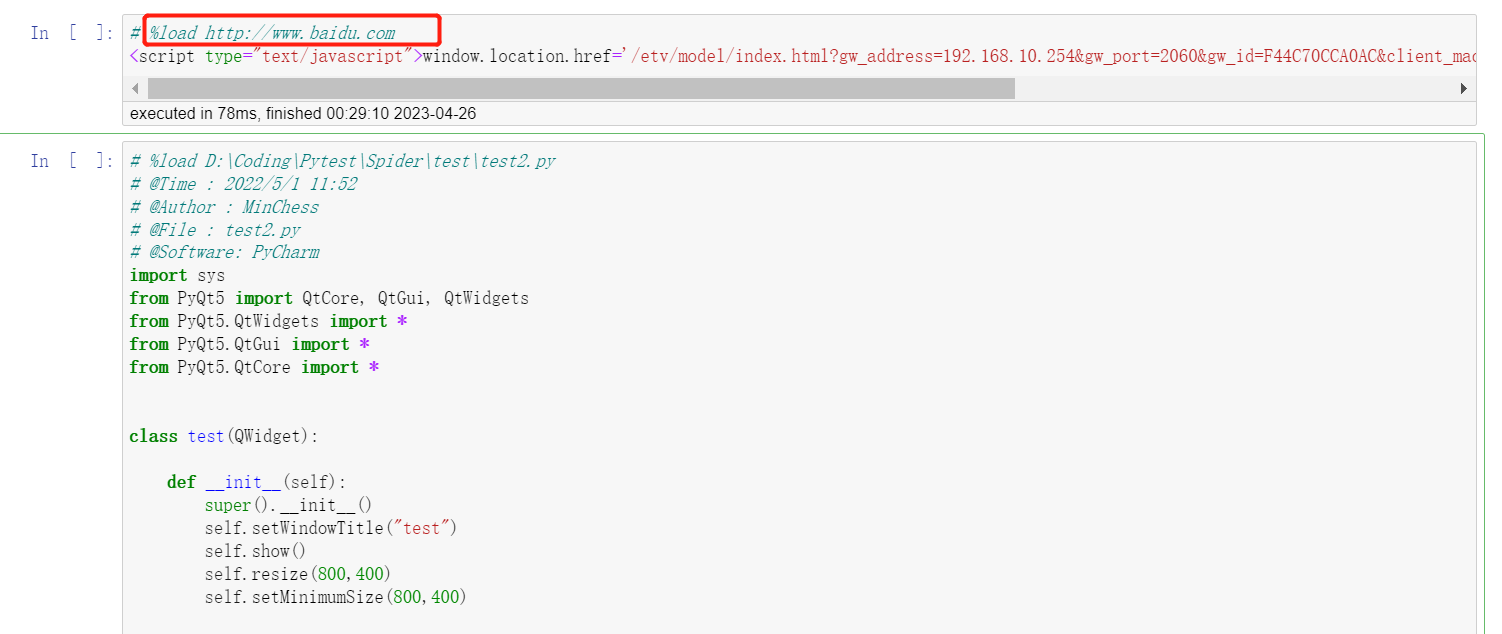
-
更多魔术命令
上面就是魔术命令的一个应用,其他的还有类似获取当前文件位置的命令等等,更多内容参考官网:https://ipython.readthedocs.io/en/stable/interactive/magics.html
8.实战
8.1一个简单的绘图
#!/usr/bin/env python
# coding: utf-8
# In[1]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# In[2]:
# 创建测试数据
df = pd.DataFrame({
'year': [2016, 2017, 2018, 2019, 2020],
'sales': [100, 130, 150, 170, 200]
})
# In[3]:
# 绘制柱状图
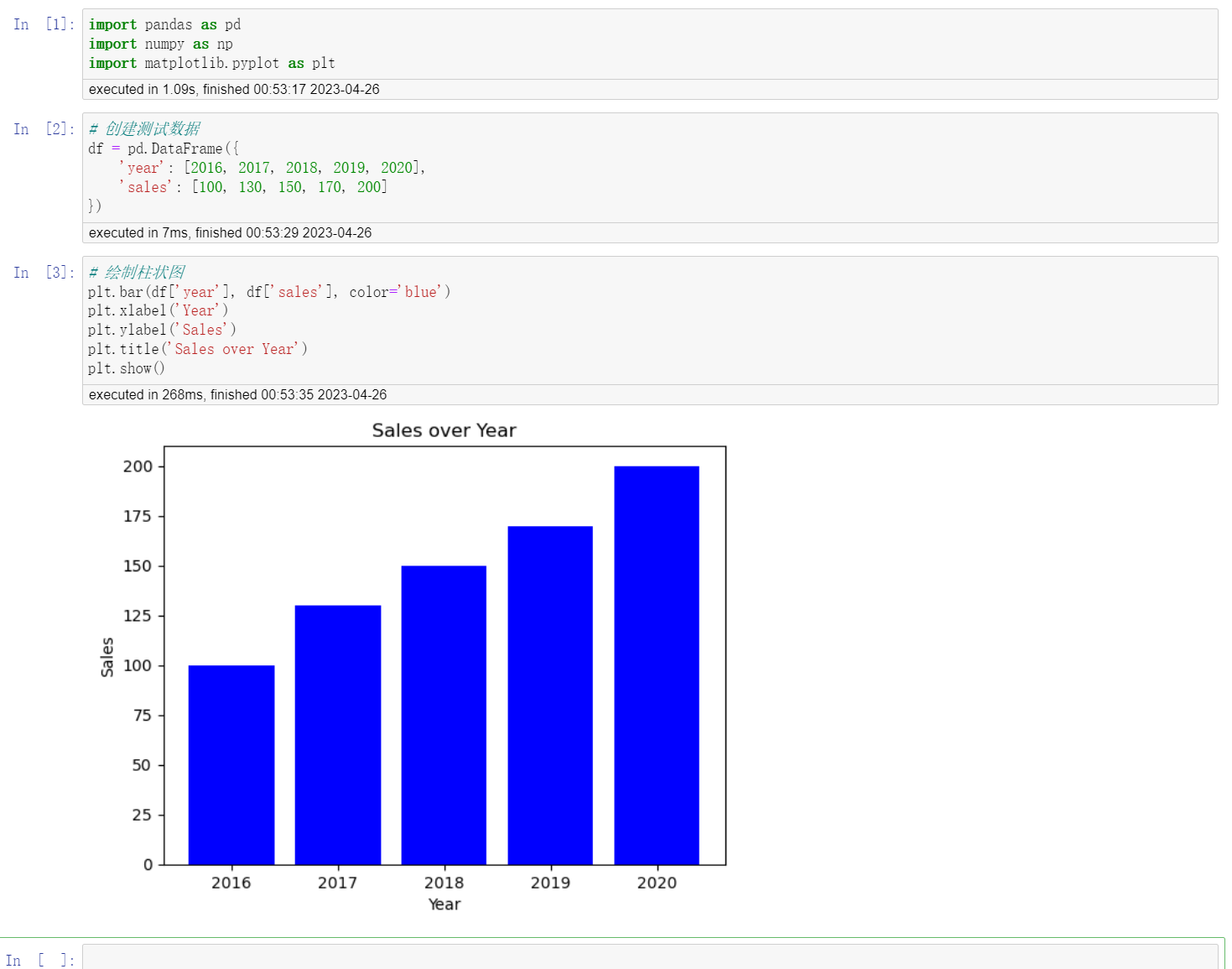
plt.bar(df['year'], df['sales'], color='blue')
plt.xlabel('Year')
plt.ylabel('Sales')
plt.title('Sales over Year')
plt.show()
# In[ ]:
三个单元格分别导入包、创建测试数据、绘图;
运行需要严格按顺序执行;
8.1爬取微博热搜
#!/usr/bin/env python
# coding: utf-8
# In[7]:
import requests
from bs4 import BeautifulSoup
import time
# In[18]:
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36',
'Cookie':'SUB=_2AkMTf37Hf8NxqwJRmPAVyG7jbol0wwrEieKlI48cJRMxHRl-yT9vqlYOtRB6OP9QKBlDDjMdGlMFok5NIqGTLxEXHcGr; SUBP=0033WrSXqPxfM72-Ws9jqgMF55529P9D9W5UiecUPRV2SWjRzBIq2X0V; SINAGLOBAL=618205954960.4446.1681196722663; UOR=www.baidu.com,weibo.com,tophub.today; _s_tentry=-; Apache=5834475057987.334.1682445226156; ULV=1682445226181:3:3:1:5834475057987.334.1682445226156:1681202990452; XSRF-TOKEN=WKel-EKSczosZuoOMXKVIH9H; WBPSESS=durPiJxsbzq5XDaI2wW0N0pbOd3fbV1w3XF-VOcj7XTJ8vDiYa5jmFydo3U2yLd3wSJp3fMJK1n5h3EzWFi1ruvJTHRYOs9aoG4rZ64JjMz9qH5LbEnhw5Cxomz5i-gj'
}
url = 'https://s.weibo.com/top/summary'
# In[19]:
try:
response = requests.get(url, headers=headers)
response.encoding = 'utf-8'
if response.status_code == 200:
print(response.text)
else:
print(f'Request failed with status code {response.status_code}')
except RequestException as e:
print(e)
# In[20]:
response_html = response.text
# In[21]:
soup = BeautifulSoup(response_html, 'lxml')
# In[22]:
hot_list = []
# In[23]:
items = soup.select('tbody > tr')
# In[31]:
for item in items:
hot_title = item.select_one('.td-02 > a').get_text(strip=True)
hot_url = 'https://s.weibo.com' + item.select_one('.td-02 > a')['href']
hot_item = {
'hot_title': hot_title,
'hot_url': hot_url
}
hot_list.append(hot_item)
# In[43]:
for i in range(len(hot_list)):
if i<10:
print(i+1,hot_list[i]["hot_title"])
具体思路是,使用requests库向新浪微博实时热搜的页面发送请求,并通过BeautifulSoup库解析返回的html内容。然后遍历html中的各个元素,提取出热搜话题的标题和链接,最后将其存储到hot_list数组中。最后再遍历一次hot_list数组,输出前十个热搜话题。
需要注意的是,这段代码访问新浪微博网站时设置了请求头和Cookie,防止因缺失必要参数而无法请求到数据。同时,由于网站的内容可能随时发生变化或者有反爬虫机制的存在,因此需要在爬取时进行一定的容错处理,确保程序运行的稳定性。

Q&A
Anaconda快捷方式打开Jupyter和命令打开的启动目录不一样
具体这里的坑就是,明明已经修改过Jupyter的启动目录了,但是通过Anaconda安装的jupyter快捷方式打开的时候,打开的启动目录还是默认的目录,但是使用命令打开的时候,启动目录已经修改成功了;
为什么?
在 Windows 上,可以通过两种方式运行 Jupyter Notebook:
- 通过命令行打开 Jupyter Notebook。
- 在 Windows 桌面上添加快捷方式,通过快捷方式打开 Jupyter Notebook。
这两种方式的区别在于,通过 Anaconda 命令行打开 Jupyter Notebook 时,启动的是 Anaconda 中当前激活的环境下安装的 Jupyter Notebook;而通过桌面快捷方式打开 Jupyter Notebook 时,启动的是指定环境下 Anaconda 中安装的 Jupyter Notebook。
为了更好地理解这个问题,以下是各个文件路径的具体解释:
C:\Anaconda3\python.exe是 Anaconda 配备的 Python 解释器执行文件的路径。C:\Anaconda3\cwp.py是一个用于改变当前工作路径到指定路径的脚本文件。C:\Anaconda3\envs\env_name是指向指定环境的路径。C:\Anaconda3\Scripts\jupyter-notebook-script.py是用于启动 Jupyter Notebook 的 Python 脚本文件。%USERPROFILE%是指向当前用户主目录的路径。通过命令行进入到 Anaconda Prompt 界面后(或者直接使用 PowerShell/CMD),输入 “jupyter-notebook” 命令,系统会自动在当前激活的 Anaconda 环境下寻找 Jupyter Notebook,并启动它。所以在这种情况下,无需使用 cwp.py 脚本文件、env_name 环境路径和 jupyter-notebook-script.py 路径来指定环境和启动脚本。
但是,如果你想从桌面上的快捷方式来启动 Jupyter Notebook,就需要指明你想运行哪个环境中的 Jupyter Notebook。为了做到这一点,快捷方式需要知道:
- Python 解释器的位置(即
C:\Anaconda3\python.exe);- 切换环境的脚本位置(即
C:\Anaconda3\cwp.py);- 想要使用的环境的位置(即
C:\Anaconda3\envs\env_name);- 启动 Jupyter Notebook 的 Python 脚本位置(即
C:\Anaconda3\Scripts\jupyter-notebook-script.py);- 用户主目录的位置(即
%USERPROFILE%)。因此,在使用桌面快捷方式启动 Jupyter Notebook 时,快捷方式实际上是通过执行如下命令来打开它的:
C:\Anaconda3\python.exe C:\Anaconda3\cwp.py C:\Anaconda3\envs\env_name C:\Anaconda3\Scripts\jupyter-notebook-script.py %USERPROFILE%这会激活指定环境,并在该环境下启动 Jupyter Notebook 执行服务。
例如,博主的路径如下,这里
D:\Coding\Anaconda3就是默认的python环境;D:\Coding\Anaconda3\python.exe D:\Coding\Anaconda3\cwp.py D:\Coding\Anaconda3 D:\Coding\Anaconda3\python.exe D:\Coding\Anaconda3\Scripts\jupyter-notebook-script.py "%USERPROFILE%/"如何修改通过快捷方式打开的Jupyter的启动目录?
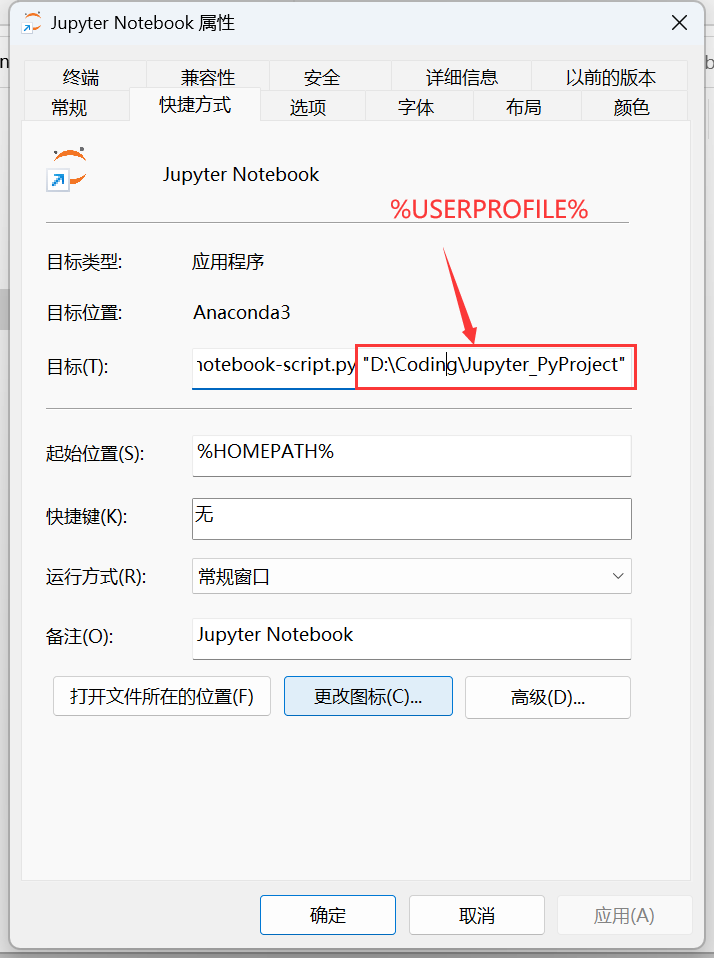
打开快捷方式文件夹,右键单击要修改的快捷方式图标,并选择 “属性”。
在 “快捷方式” 选项卡下,找到 “目标” 字段,目标内的命令如下,
%USERPROFILE%有没有双引号包含都不影响;C:\Anaconda3\python.exe C:\Anaconda3\cwp.py C:\Anaconda3\envs\env_name C:\Anaconda3\Scripts\jupyter-notebook-script.py %USERPROFILE%将
%USERPROFILE%完全替换为你设定的启动目录的路径,引号不影响。
点击 “应用” 按钮保存修改,并退出 “属性” 窗口就大功告成了。
界面汉化
网上界面汉化的教程一大堆,什么改配置文件、新增用户变量、启动命令后面加
--NotebookApp.locale=zh_CN指定语言环境,试过都没有效果,不过也不知道是不是我电脑环境的问题,这个没有排除…但是好像安装扩展库就可以,不过这个也有待确认,琢磨了很久,没琢磨明白,全是坑…
知道的网友可以留言告诉我一下具体咋汉化…
Jupyter notebook和IDE的适用场景
Jupyter适用场景: 数据处理与分析:
- 数据可视化:Jupyter提供了交互性良好的可视化环境,使得数据探索变得更加简单直观。
- 机器学习建模:通过使用Jupyter Notebook进行数据预处理、特征工程和模型训练等步骤,提高建模效率和模型的准确性。
- 数据清洗:利用Jupyter进行数据分析和数据清洗,对于大量数据清洗工作尤为有效。
- 数据分析:Jupyter交互式的环境使得数据分析变得更加方便,运行代码并马上看到结果。
- 统计分析:Jupyter支持Python中常用的统计分析库,如NumPy、SciPy、pandas和statsmodels等。
- 可重复研究:借助Jupyter的notebook功能,将实验过程记录下来并共享给同事或者社区用户,利于可重复性研究。
- 实时数据流分析:使用Jupyter和Kafka结合,对大数据进行实时数据流分析和可视化展示。
- 巨大的数据集可视化:使用Jupyter和Dask等库,能够将大规模数据集转换成可视化展现的图表,便于用户理解。
- 研究证明:许多科学家和研究人员都使用Jupyter作为探索性研究的工具,非常方便快捷。
- 自然语言处理:利用Jupyter Notebook进行各种自然语言处理任务,如文本处理、词向量生成等。
IDE适用场景: 项目开发:
- 代码重构:IDE提供了更多的辅助手段,如代码补全、代码格式化、自动调试等,提高代码重构的效率。
- 大型项目开发:IDE支持更加复杂的文件组织、项目管理和版本控制,能够满足大型项目的需求。
- 单元测试和集成测试:IDE内置了一些调试工具,如单元测试器和集成测试工具,能够帮助开发者更加快速地定位和解决问题。
- API开发:IDE支持RESTful API的开发,利于接口设计、测试和文档编写。
- 可视化界面开发:IDE中支持窗体设计器等工具,快速创建并完成可视化界面的开发。
- 桌面软件开发:IDE支持Python GUI开发库(如Tkinter、WxPython等),有助于在Python中构建桌面应用程序。
- Web应用程序开发:通过使用IDE和Flask、Django等Web框架,可以更快地搭建和开发Web应用。
- 数据库应用:IDE支持数据库操作,利于程序与RDBMS或NO-SQL数据库的交互。
- 多人协同开发:IDE支持代码版本控制和代码托管,方便团队进行代码协同开发。
- 代码重用:代码重用是提高开发效率的重要手段,IDE中支持打包、发布和分享代码库,加速代码编写。
Jupyter notebook和IDE的适用项目类型与举例
Jupyter Notebook 适合的项目
数据科学、机器学习和人工智能等领域的项目:
这些项目通常需要处理大量的数据,进行数据预处理、数据可视化、模型开发和评估。使用Jupyter Notebook 可以提供交互式环境,方便数据科学家和机器学习工程师们快速实验和迭代模型,同时也支持将代码、注释和可视化结果整合为一个文档来展示。
例如:使用 Scikit-learn 对鸢尾花数据集进行分类模型的开发和评估。
探索性编程和原型开发等项目:
这些项目需要快速验证代码方案,协作与分析的过程中也可能需要频繁地共享代码和文档。使用Jupyter Notebook 可以轻松地实现代码与文档的交互,同时支持 Markdown 和 Latex 等格式的文档展示(即所谓的 NBconvert),使得代码、注释、结果和文档可以整合在一起,方便团队成员协作和项目管理。
例如: 使用 Flask 开发一个简单的 Web 应用程序,可以先使用 Jupyter Notebook 原型化实现,再使用 IDE 进行后期开发。
教学和演示方面的项目:
Jupyter Notebook 可以将代码、注释和结果整合到一起作为一个交互式文档来展示和分享。这使得它成为一个出色的教学工具,可以用于讲解和展示数据相关的主题,并且可以通过 Markdown 和 Latex 等格式进行细致的排版和思路展现。
例如:编写一个数据科学教学笔记,包括数据集介绍、数据分析过程、可视化展示和建模流程。
IDE 适合的项目
大型 Python 应用程序的开发:
IDE 适合处理大型项目,具有更好的代码组织、架构、调试和性能优化的支持,可以帮助开发者更好地管理和维护大型项目。
例如:使用 Django 框架开发一个复杂的 Web 应用程序。
调试、测试和性能优化等方面的项目:
IDE 提供了强大的断点调试和测试支持,同时也提供了性能分析和优化的工具,有利于在长时间运行、高并发等场景下进行性能优化和问题排查。
例如:使用 PyCharm 进行 Python 代码的 debug 和 CPU profiling。
持久化,部署和集成等方面的项目:
IDE 支持 Python 代码的打包、发布、版本控制和持续集成,具有更好的生产力,可以帮助开发者更好地部署和管理项目。
例如: 使用 Visual Studio 打包和发布 Python 应用程序到云上。
需要使用 Python 高级功能和库的项目:
IDE 提供了更丰富的编辑器支持以及各种第三方插件,可以轻松处理并行计算、多线程处理、异步编程、机器学习框架等高级功能和库。
例如:使用 PyTorch 或 TensorFlow 框架进行深度学习模型的开发和训练。
jupyter notebook安装Nbextensions不显示问题
伴随这个问题有一个报错,就是启动jupyter notebook后,命令窗口报错
404 GET /static/components/marked/lib/marked.js解决办法:
来到python安装目录:
Lib\site-packages\nbclassic\static\components\marked\lib\找到marked.umd.js,直接复制并重命名marked.js,重启jupyter notebook。
上一个单元格导的包下一个单元格可以使用吗
可以使用。
在 Jupyter 中,如果一个单元格中导入了某个 Python 包,那么下一个单元格是可以直接使用该包的。这是因为在 Jupyter 中,所有单元格都运行在同一个 Python 内核中,所以它们之间可以共享变量、函数和模块等资源。
需要注意的是,如果您在导入模块时发生了错误,比如因为模块不存在或者路径设置不正确等原因,后续的单元格也会受到影响。此外,如果您使用了一些需要进行初始化的模块,比如 TensorFlow 或者 PyTorch 等深度学习框架,建议您在每个单元格开头手动进行初始化操作,以避免出现意外的错误。
如果您遇到了模块无法被正确导入的问题,可以尝试在单元格中手动添加 sys.path,将需要导入的模块所在的路径加入到 sys.path 中。例如:
import sys sys.path.append('/path/to/module/') # 将模块所在的路径添加到 sys.path 中 import module_name # 导入模块
jupyter中单元格之间的关系
在Jupyter Notebook中,单元格是最基本的单位,用户可以在其中编写代码、插入文本、图像、表格等内容,每个单元格可以看作是一个独立的小程序。这些单元格之间存在着以下几种关系:
- 执行顺序:Jupyter Notebook中的单元格按照它们的位置逐一执行,从上至下逐个执行。如果用户将一个循环拆分成两个单元格,那么第二个单元格就无法访问第一个单元格定义的变量,也就无法正确执行循环。
- 依赖关系:有时候一个单元格可能需要另一个单元格的输出结果来进行计算或者展示,这时候就需要通过"Shift+Enter"运行前一个单元格以产生输出结果,再运行当前单元格以完成计算或者展示。如果前一个单元格没有被执行或者输出结果不符合要求,会导致当前单元格出现错误。
- 顺序依赖性:有些单元格必须以特定的顺序执行,否则会出现错误。例如,在创建一个图表时,必须先定义图表的数据,然后才能使用数据绘制图表。



评论区