

本部分是web挖掘课程的一个作业,大部分是基于python实现的,而且就是nlp相关的操作,所以记录在这里了。
有如下的文档集合:
| d1 | 水果有西瓜水果,菠萝水果,苹果水果,其它水果。 |
|---|---|
| d2 | 水果还有苹果,桃子,其它水果。 |
| d3 | 蔬菜好吃,水果也好吃。 |
| d4 | 苹果,西瓜,苹果都是好吃的。 |
| d5 | 好吃的水果有西瓜、苹果,还有菠萝水果,都是水果。 |
停用词表(stop words):的,地,得,有,也,都是,还有,其它。
一、请给出上述文档集合进行分词和去除停用词之后的结果。
1.1 分词
- 实现思路
针对文档文档进行分词,利用python中的jieba库可以很轻松的实现。即首先将文档提取到一个文件内,然后遍历处理即可。
- 核心代码
# -*- coding: utf-8 -*-
# @Time : 2022/5/20 17:12
# @Author : MinChess
# @File : jiebacut.py
# @Software: PyCharm
import jieba
import re
cut= ""
all = ""
for line in open('data.txt', encoding='utf-8'):
line.strip('\n')
seg_list = jieba.cut(line,cut_all=False)
cut= (" ".join(seg_list))
print(cut)
all += cut
print(all)
- 分词结果
水果 有 西瓜 水果 , 菠萝 水果 , 苹果 水果 , 其它 水果 。
水果 还有 苹果 , 桃子 , 其它 水果 。
蔬菜 好吃 , 水果 也 好吃 。
苹果 , 西瓜 , 苹果 都 是 好吃 的 。
好吃 的 水果 有 西瓜 、 苹果 , 还有 菠萝 水果 , 都 是 水果 。
- 自定义词表以及标点符号的处理
上述处理的结果明显有一定的问题,首先是标点符号是不需要的,其次的分词结果有偏差,所以要进行进一步的处理。
自定义词表根据jieba库的方法进行实现,即我们建立一个自定义的词库,利用
jieba.load_userdict方法提前加载词库即可。标点符号的处理是利用正则表达式将其删除,也就是利用python自有库
re执行,核心代码就一行text = re.sub('\W*', '', line)
- 改进后的代码
# -*- coding: utf-8 -*-
# @Time : 2022/5/20 17:12
# @Author : MinChess
# @File : jiebacut.py
# @Software: PyCharm
import jieba
import re
cut= ""
all = ""
file_userdict = 'dict.txt' #自定义词表
jieba.load_userdict(file_userdict)
for line in open('data.txt', encoding='utf-8'):
line.strip('\n')
text = re.sub('\W*', '', line)
seg_list = jieba.cut(text,cut_all=False)
# seg_list = jieba.cut(line,cut_all=False)
cut= (" ".join(seg_list))
print(cut)
all += cut
print(all)
all_list = all.split()
print(all_list)
- 最终结果
水果 有 西瓜 水果 菠萝 水果 苹果 水果 其它 水果
水果 还有 苹果 桃子 其它 水果
蔬菜 好吃 水果 也 好吃
苹果 西瓜 苹果 都是 好吃 的
好吃 的 水果 有 西瓜 苹果 还有 菠萝 水果 都是 水果
- 列表格式
['水果', '有', '西瓜', '水果', '菠萝', '水果', '苹果', '水果', '其它', '水果水果', '还有', '苹果', '桃子', '其它', '水果蔬菜', '好吃', '水果', '也', '好吃苹果', '西瓜', '苹果', '都是', '好吃', '的好吃', '的', '水果', '有', '西瓜', '苹果', '还有', '菠萝', '水果', '都是', '水果']
1.2 停用词
-
实现思路
将停用词写入数组,直接遍历判断是否包含,如果包含就删除。直接在上面的代码中插入核心代码即可。
-
核心代码
stop_words = ['的','地','得','有','也','都是','还有','其它'] #自定义停用词表
for word in cut_list:
if word not in stop_words:
if word != '\n' and word != " ":
outstr += word
outstr += " "
- 完整代码
# -*- coding: utf-8 -*-
# @Time : 2022/5/20 17:12
# @Author : MinChess
# @File : jiebacut.py
# @Software: PyCharm
import jieba
import re
cut= ""
all = ""
outstr = ""
stop_words = ['的','地','得','有','也','都是','还有','其它'] #自定义停用词表
file_userdict = 'dict.txt' #自定义词表
jieba.load_userdict(file_userdict)
for line in open('data.txt', encoding='utf-8'):
line.strip('\n')
text = re.sub('\W*', '', line)
cut_list = jieba.cut(text,cut_all=False)
for word in cut_list:
if word not in stop_words:
if word != '\n' and word != " ":
outstr += word
outstr += " "
cut= ("".join(outstr))
outstr = ""
print(cut)
all += cut
print(all)
all_list = all.split()
print(all_list)
- 停用词后结果
水果 西瓜 水果 菠萝 水果 苹果 水果 水果
水果 苹果 桃子 水果
蔬菜 好吃 水果 好吃
苹果 西瓜 苹果 好吃
好吃 水果 西瓜 苹果 菠萝 水果 水果
- 列表格式
['水果', '西瓜', '水果', '菠萝', '水果', '苹果', '水果', '水果', '水果', '苹果', '桃子', '水果', '蔬菜', '好吃', '水果', '好吃', '苹果', '西瓜', '苹果', '好吃', '好吃', '水果', '西瓜', '苹果', '菠萝', '水果', '水果']
二、请给出上述文档集合的词项-文档关联矩阵。
- 实现思路
根据词项-文档矩阵的定义,可以得出基本实现思路,那就是首先获取基本的去重词组,进一步遍历词组,去文档中进行匹配查询,如果存在,即在对应的位置设置为1,不存在就为0。
- 核心代码
# -*- coding: utf-8 -*-
# @Time : 2022/5/20 19:08
# @Author : MinChess
# @File : matrix.py
# @Software: PyCharm
from prettytable import PrettyTable
import numpy as np
docu={'d1':'水果 西瓜 水果 菠萝 水果 苹果 水果 水果',
'd2':'水果 苹果 桃子 水果',
'd3':'蔬菜 好吃 水果 好吃',
'd4':'苹果 西瓜 苹果 好吃',
'd5':'好吃 水果 西瓜 苹果 菠萝 水果 水果',}
all_words = []
file_index = [] #存储文档索引
for i in docu.values():
cut = i.split()
all_words.extend(cut)
set_all_words = set(all_words)
for i in docu.keys():
file_index.append(i)
matrix = {}
matrix['file'] = file_index
for b in set_all_words:
temp = []
for j in docu.keys():
field = docu[j]
split_fielt = field.split()
if b in split_fielt:
temp.append(1)
else:
temp.append(0)
matrix[b] = temp
for i in matrix.keys():
a = []
if(i=='file'):
a.append(i)
a.extend(matrix[i])
table = PrettyTable(a)
else:
a.append(i)
a.extend(matrix[i])
table.add_row(a)
print(table)
- 关联矩阵
+------+----+----+----+----+----+
| file | d1 | d2 | d3 | d4 | d5 |
+------+----+----+----+----+----+
| 西瓜 | 1 | 0 | 0 | 1 | 1 |
| 蔬菜 | 0 | 0 | 1 | 0 | 0 |
| 苹果 | 1 | 1 | 0 | 1 | 1 |
| 桃子 | 0 | 1 | 0 | 0 | 0 |
| 好吃 | 0 | 0 | 1 | 1 | 1 |
| 水果 | 1 | 1 | 1 | 0 | 1 |
| 菠萝 | 1 | 0 | 0 | 0 | 1 |
+------+----+----+----+----+----+
三、请建立上述文档集合的倒排索引。
- 倒排索引
倒排索引是一种检索方式,比如存入数据库的数据是存一篇文章进去,然而检索时我们经常需要通过关键词检索,所以提前做好倒排索引即可方便检索,而省略掉全表扫描的问题了,这是一种用空间换时间的方法。
对每个词项word,,记录所有包含word的文档列表,每篇文档用唯一ID标识。
根据上述内容,设计实现就比较简单了,同样先整理一份去重词表,再逐句匹配,存在就添加索引,这里的索引直接用给定文档的Key作为唯一ID。
- 核心代码
# -*- coding: utf-8 -*-
# @Time : 2022/5/20 18:34
# @Author : MinChess
# @File : invertindex.py
# @Software: PyCharm
docu={'d1':'水果 西瓜 水果 菠萝 水果 苹果 水果 水果',
'd2':'水果 苹果 桃子 水果',
'd3':'蔬菜 好吃 水果 好吃',
'd4':'苹果 西瓜 苹果 好吃',
'd5':'好吃 水果 西瓜 苹果 菠萝 水果 水果',}
all_words = []
for i in docu.values():
cut = i.split()
all_words.extend(cut)
set_all_words = set(all_words)
print(set_all_words)
invert_index = dict()
for b in set_all_words:
temp = []
for j in docu.keys():
field = docu[j]
split_field = field.split()
if b in split_field:
temp.append(j)
invert_index[b] = temp
# print(invert_index)
for k, v in invert_index.items():
print("%s:%s" % (k, v))
- 倒排索引结果
苹果:['d1', 'd2', 'd4', 'd5']
水果:['d1', 'd2', 'd3', 'd5']
西瓜:['d1', 'd4', 'd5']
蔬菜:['d3']
桃子:['d2']
菠萝:['d1', 'd5']
好吃:['d3', 'd4', 'd5']
四、请建立上述文档集合的词频矩阵。
- 实现思路
词频矩阵就是词在文档内词频的矩阵分布情况,所以实现较为简单,计算词频就行。
- 核心代码
# -*- coding: utf-8 -*-
# @Time : 2022/5/20 21:45
# @Author : MinChess
# @File : wordfrequency2.py
# @Software: PyCharm
from prettytable import PrettyTable
import numpy as np
docu={'d1':'水果 西瓜 水果 菠萝 水果 苹果 水果 水果',
'd2':'水果 苹果 桃子 水果',
'd3':'蔬菜 好吃 水果 好吃',
'd4':'苹果 西瓜 苹果 好吃',
'd5':'好吃 水果 西瓜 苹果 菠萝 水果 水果',}
all_words = []
file_index = [] #存储文档索引
for i in docu.values():
cut = i.split()
all_words.extend(cut)
set_all_words = set(all_words)
for i in docu.keys():
file_index.append(i)
matrix = {}
matrix['word'] = set_all_words
for d in file_index:
print(d)
temp = []
for b in set_all_words:
field = docu[d]
split_fielt = field.split()
count = 0
for word in split_fielt:
if(b==word):
count =count + 1
temp.append(count)
matrix[d] = temp
print(matrix)
for i in matrix.keys():
a = []
if(i=='word'):
a.append(i)
a.extend(matrix[i])
table = PrettyTable(a)
else:
a.append(i)
a.extend(matrix[i])
table.add_row(a)
print(table)
- 词频矩阵结果
+------+------+------+------+------+------+------+------+
| word | 桃子 | 水果 | 苹果 | 菠萝 | 蔬菜 | 西瓜 | 好吃 |
+------+------+------+------+------+------+------+------+
| d1 | 0 | 5 | 1 | 1 | 0 | 1 | 0 |
| d2 | 1 | 2 | 1 | 0 | 0 | 0 | 0 |
| d3 | 0 | 1 | 0 | 0 | 1 | 0 | 2 |
| d4 | 0 | 0 | 2 | 0 | 0 | 1 | 1 |
| d5 | 0 | 3 | 1 | 1 | 0 | 1 | 1 |
+------+------+------+------+------+------+------+------+
五、请建立上述文档集合的TFIDF权重矩阵。
-
TF-IDF算法
词频(TF)=某个词在文档中出现的次数/文档的总词数
逆文档频率(IDF)=log(语料库的文档总数/(包含该词的文档数+1))
TF−IDF=词频(TF)×逆文档频率(IDF)
-
代码实现
个人实现算法会产生一定的偏差,所以直接使用python下
sklearn包进行实现。 -
核心代码
# -*- coding: utf-8 -*-
# @Time : 2022/5/20 22:08
# @Author : MinChess
# @File : tfidf.py
# @Software: PyCharm
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from prettytable import PrettyTable
vectorizer = CountVectorizer()
transformer = TfidfTransformer()
corpus = ["水果 西瓜 水果 菠萝 水果 苹果 水果 水果", "水果 苹果 桃子 水果","蔬菜 好吃 水果 好吃","苹果 西瓜 苹果 好吃","好吃 水果 西瓜 苹果 菠萝 水果 水果",]
result_list2 = transformer.fit_transform(vectorizer.fit_transform(corpus)).toarray().tolist()
word = vectorizer.get_feature_names()
print('词典为:')
print(word)
print('归一化后的tf-idf值为:')
count = 1
matrix = {}
matrix['word'] = word
for weight in result_list2:
id = "d"+str(count)
matrix[id] = weight
count = count + 1
print(weight)
for i in matrix.keys():
a = []
if(i=='word'):
a.append(i)
a.extend(matrix[i])
table = PrettyTable(a)
else:
a.append(i)
a.extend(matrix[i])
table.add_row(a)
print(table)
- 计算结果
词典为:
['好吃', '桃子', '水果', '苹果', '菠萝', '蔬菜', '西瓜']
归一化后的tf-idf值为:
[0.0, 0.0, 0.9211389809848156, 0.1842277961969631, 0.26382397573591737, 0.0, 0.21899773205574488]
[0.0, 0.6217300025236953, 0.7005436768464253, 0.35027183842321263, 0.0, 0.0, 0.0]
[0.7593397076753798, 0.0, 0.3193902502932603, 0.0, 0.0, 0.5669154049459911, 0.0]
[0.4549836381875804, 0.0, 0.0, 0.7654931599715217, 0.0, 0.0, 0.4549836381875804]
[0.30819636211301865, 0.0, 0.7777934874715958, 0.2592644958238653, 0.3712805096050312, 0.0, 0.30819636211301865]
- TFIDF权重矩阵

| 好吃 | 桃子 | 水果 | 苹果 | 菠萝 | 蔬菜 | 西瓜 | |
|---|---|---|---|---|---|---|---|
| d1 | 0 | 0 | 0.921138980984815 | 0.184227796196963 | 0.263823975735917 | 0 | 0.218997732055744 |
| d2 | 0 | 0.621730002523695 | 0.700543676846425 | 0.350271838423212 | 0 | 0 | 0 |
| d3 | 0.759339707675379 | 0 | 0.31939025029326 | 0 | 0 | 0.566915404945991 | 0 |
| d4 | 0.45498363818758 | 0 | 0 | 0.765493159971521 | 0 | 0 | 0.45498363818758 |
| d5 | 0.308196362113018 | 0 | 0.777793487471595 | 0.259264495823865 | 0.371280509605031 | 0 | 0.308196362113018 |
六、将你的姓名的拼音转换为soundex编码。
-
实现原理
- 编码表
Soundex Code Letters 0 a e h i o u w y 1 b f p v 2 c g j k q s x z 3 d t 4 l 5 m n 6 r -
提取字符串的首字母作为soundex的第一个值。
-
按照上面的字母对应规则,将后面的字母逐个替换为数字。如果有连续的相等的数字,只保留一个,其余的都删除掉。并去除所有的0。
-
如果结果超过4位,取前四位;如果结果不足4位向后补0。
-
代码实现
根据上面的原理,我们只需要定义一个字典,然后用我们的字符串去匹配替换即可,这里使用正则表达式。
# -*- coding: utf-8 -*-
# @Time : 2022/5/20 23:26
# @Author : MinChess
# @File : soundex.py
# @Software: PyCharm
import re
string = "tianqi"
string = string.lower()
law = {'aehiouwy' : 0,
'bfpv': 1,
'cgjkqsxz': 2,
'dt': 3,
'l': 4,
'mn': 5,
'r': 6}
temp_string = string[1:]
print(temp_string)
for key, value in law.items():
temp_string = re.sub('[{}]'.format(key), str(value), temp_string)
temp_string = re.sub('0', '', temp_string)
result = []
for char in temp_string:
if char not in result:
result.append(char)
print(result)
# result.remove(result[0])
result = string[0] + ''.join(result[:3])
while len(result) != 4:
result += '0'
print(string,'的Soundex编码为:',result)
- 最终转换结果
tianqi 的Soundex编码为: t520
七、如果查询词是“水果”,其使用向量空间模型排序结果是?为什么?
-
结果
结果是 d1、d2、d3、d5
-
原理简述
判断Term之间的关系从而得到文档相关性的过程,也即向量空间模型的算法(VSM)。
把文档看作一系列词(Term),每一个词(Term)都有一个权重(Term weight),不同的词(Term)根据自己在文档中的权重来影响文档相关性的打分计算。于是把所有此文档中词(Term)的权重(Term weight) 看作一个向量。
Document = {term1, term2, …… ,term N}
Document Vector = {weight1, weight2, …… ,weight N}
同样我们把查询语句看作一个简单的文档,也用向量来表示。
Query = {term1, term 2, …… , term N}
Query Vector = {weight1, weight2, …… , weight N}
把所有搜索出的文档向量及查询向量放到一个N维空间中,每个词(term)是一维。-
公式如下:
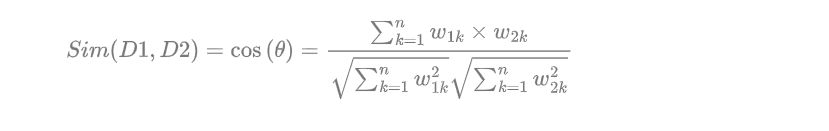
-
-
TF-IDF计算
文档的TF-IDF在第五题中已经计算了,所以只需要计算查询语句的TF-IDF,因为只有一个词,所以其为1
-
相关性系数计算
- 查询词对应各文档的权重表格如下:
“水果”的TF-IDF d1 0.9211389809848156 d2 0.7005436768464253 d3 0.3193902502932603 d4 0.0 d5 0.7777934874715958 查询语句(Q) 1 -
计算5篇文档的相关系数

-
计算结果分别为
1、1、1、不存在、1
-
原因总结
根据计算结果可以看出,由于查询文档的词数原因,计算出来的相关系数只有1和不存在两种情况,所以查询结果是默认排序。
八、试述信息检索常用评价指标及其定义。
-
正确率
返回的结果中真正相关结果的比率,也称为查准率,P∈[0,1]
-
召回率
返回的相关结果数占实际相关结果总数的比率,也成为查全率,R∈[0,1]。
-
F值
是召回率R与正确率P的调和平均值,表示召回率的重要程度是正确率的β倍,β>1更重视召回率,β<1更重视正确率。
-
精确率
是所有判定中正确的比率
-
正确率-召回曲线(P-R曲线)
P-R曲线就是以召回率(recall)为横坐标,精确率(precision)为纵坐标的曲线图
-
Break Point
P-R曲线上 P=R的那个点
-
11点平均正确率
在召回率分别为0,0.1,0.2,…,1.0的十一个点上的正确率求平均,等价于插值的AP
-
宏平均
对每个查询求出某个指标,然后对这些指标进行算术平均。宏平均对所有查询一视同仁(保护弱者)
-
微平均
将所有查询视为一个查询,将各种情况的文档总数求和,然后进行指标的计算。微平均受返回相关文档数目比较大的查询影响
-
MAP
对所有查询的AP求宏平均。具体而言,单个主题的平均准确率是每篇相关文档检索出后的准确率的平均值。主集合的平均准确率(MAP)是每个主题的平均准确率的平均值。MAP 是反映系统在全部相关文档上性能的单值指标
-
ROC曲线
受试者工作特征曲线(receiver operating characteristic curve),又称为敏感度曲线。以真阳率(True positive rate)或者敏感度(召回率)为纵坐标,假阳率(1-特异度)为横坐标绘制的曲线。
-
真阳率
也称命中率,TPR = TP / P = TP / (TP + FN),表示当前分到正样本中真实的正样本所占所有正样本的比例。
-
假阳率
也称错误命中率,FPR = FP / N = FP / (FP + TN),表示当前被错误分到正样本类别中真实的负样本所占所有负样本总数的比例
-
AUC
Area Under Curve被定义为ROC曲线下的面积,是反映敏感度和特异度连续变量的综合指标, 它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感度和特异度,再以敏感度为纵坐标、(1-特异度)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高
-
覆盖率
假定用户已知的相关文档集合为U,检索结果和U的交集为Ru,则可以定义覆盖率(Coverage) C=|Ru|/|U|,表示系统找到的用户已知的相关文档比例
-
出新率
假定检索结果中返回一些用户以前未知的相关文档Rk,则可以定义出新率(Novelty Ratio) N=|Rk|/(|Ru|+|Rk|),表示系统返回的新相关文档的比例
-
Bpref
Bpref(Binary preference),2005年首次引入到TREC的Terabyte任务中。只考虑对返回结果列表中的经过判断后的文档进行评价。在相关性判断完整的情况下,bpref具有与MAP相一致的评价结果。在测试集相关性判断不完全的情况下,bpref依然具有很好的应用(比MAP更好)。这个评价指标主要关心不相关文档在相关文档之前出现的次数
-
GMAP
TREC2004 Robust 任务引进
-
NDCG
每个文档不仅仅只有相关和不相关两种情况,而是有相关度级别,比如0,1,2,3。我们可以假设,对于返回结果:相关度级别越高的结果越多越好;相关度级别越高的结果越靠前越好。图形直观,易解释;支持非二值的相关度定义,比P-R曲线更精确;能够反映用户的行为特征(如:用户的持续性persistence)
,但是相关度的定义难以一致;需要参数设定。
-
MRR
正确检索结果值在检索结果中的排名来评估检索系统的性能
-
HR
在top-K推荐中,HR是一种常用的衡量召回率的指标
九、请给出一个完整的搜索系统的组成框架,并简述各部分的功能。
- 框架图
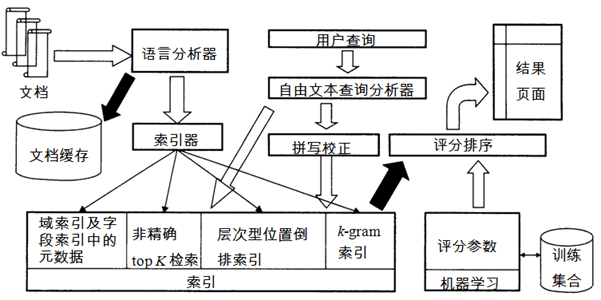
-
功能说明
-
文档预处理(语言及其他处理)
包括文档格式处理、文档语言识别、文档编码识别,即在文本分类索引之前,先对文档进行预处理。
-
位置信息索引
在倒排记录表中,对每个term在每篇文档中的每个位置(偏移或者单词序号)进行存储。基于位置信息索引,能够处理短语查询(phrase query),也能处理邻近式查询(proximity query)。
-
多层次索引
建立多层索引,每层对应索引词项的重要性。查询处理过程中,从最高层索引开始。如果最高层索引已经返回至少k (比如, k = 100)个结果,那么停止处理并将结果返回给用户。如果结果 < k 篇文档,那么从下一层继续处理,直至索引用完或者返回至少k 个结果为止。
-
拼写校正
主要用于纠正待索引文档和纠正用户的查询,有两种拼写校正的方法:
词独立(Isolated word)法:只检查每个单词本身的拼写错误,如果某个单词拼写错误后变成另外一个单词,则无法查出。
上下文敏感(Context-sensitive)法:纠错时要考虑周围的单词,能纠正上例中的错误。
-
k-gram索引(针对通配查询和拼写校正)
比轮排索引空间开销要小,枚举一个词项中所有连读的k个字符构成的k-gram 。k-gram索引用于查找词项,基于查询包含的k-gram查找词项。
-
查询处理
给定查询 Q, 找离它最近的先导者L,从L及其追随者集合中找到前K个与Q最接近的文档返回。
-
文档评分
即对查询-文档匹配评分计算,通过评分方法得出文档集中相关度从高到低的排名,包括Jaccard系数等。
-
以词项为单位的处理方式
通常包括词条化、中文分词、处理停用词、词条归一化成词项,是指将词类经过一系列处理之后形成用于处理的词项。
-
文档缓存(cache)
用它来生成文档摘要(snippet)
-
域索引
按照不同的域进行索引,如文档正文,文档中所有高亮的文本,锚文本、元数据字段中的文本等等
-
邻近式排序
如查询词项彼此靠近的文档的得分应该高于查询词项距离较远的文档
-
查询分析器
查询ODBC数据源(包括数据库、TXT/CSV文件、EXCEL文件)的数据
-


评论区