

1. 前言
1.1. 本文背景
本文主要记录的是两个 S3 服务的命令行工具,也就是 s3cmd 和 s5cmd;
主要解决的需求就是使用这两个工具,自动同步 S3 服务上的文件到本地;具体场景如下:
个人博客网站(blog.jiumoz.top)所有的图片都是存储在 Cloudflare R2 上的,因为它有不少的免费额度,包括存储、流量、访问次数等;我写博客的是使用的 Typora+Piclist,然后上传到博客后台。肯定是速度有一定的缺陷,但是考虑成本和流量,所以先将就一下吧,而且它并没有很慢。
但是还有一个致命的问题,那就是上传 CSDN 的时候,CSDN 并不能转存 CloudFlare R2 的图片,这让我很难受,在网上找了很多办法,都没用;后来我把图片放到自己服务器上,新建一个静态网站,然后再把图片链接替换后,上传 CSDN 完全没问题,转存基本没有失败的,所以我就想把图片都在服务器上放一份,然后上传 CSDN 的时候,把 R2 的链接全部换成服务器上的链接再上传就没问题了;
紧接着就有几个问题:
-
怎么批量替换图片链接
-
最简单的办法
如果你使用的是 Typora ,那么直接
Ctrl+H就可以了;
-
费点劲的办法
-
-
怎么自动同步 S3 的文件到服务器对应目录
本文要解决的问题!
如果你只想看怎么自动同步的话,可以直接跳转到 2.3.2 章节了,里面有记录;
解决这两个问题,那就都好说了;
如果你没有这样的需求,我也推荐你往下看一看,因为本文要介绍的这些工具并不简单,不管是上传、下载、备份等都能通过这些工具实现,详细内容往下看吧!
1.2. 对象存储与S3 协议
其实能看这篇文章,大概率是对对象存储以及 S3 协议有所了解的,所以这里就简单介绍一下,不深入;
对象存储是一种为存储大量非结构化数据设计的技术,适合存放图片、视频、文档、备份文件等大文件。和传统的文件存储不同,对象存储将数据视为“对象”,每个对象都有一个唯一的标识符和一组元数据(描述信息),因此无需复杂的文件路径管理。对象存储的特点是可扩展性强,适合海量数据存储需求,广泛应用于云服务中。
S3协议是由 Amazon 设计的一种标准化接口,用于访问和管理存储在云中的对象。S3 协议定义了如何存储、读取、删除对象,并控制访问权限。许多对象存储服务都支持 S3 协议,意味着用户可以用相同的API或客户端工具来访问不同的存储服务(比如AWS S3、MinIO等)。现在主流的对象存储服务,基本都支持 S3 协议,所以日常需要接触对象存储的话就了解 S3 是有必要的;
2. S3cmd使用教程
2.1. 简介
GitHub 地址:https://github.com/s3tools/s3cmd

s3cmd 是一个用于管理 Amazon S3 和兼容 S3 协议存储(如 DigitalOcean Spaces、Alibaba OSS)的开源命令行工具。它支持文件的上传、下载、同步、权限管理、版本控制和数据加密,适合需要频繁进行文件管理的开发者。相比 AWS CLI,s3cmd 更简洁、灵活,非常适合小型开发团队和个人用户。
- 功能特点:
- 丰富的操作命令:支持上传、下载、删除、复制、移动文件和文件夹等基本操作。还可以列出存储桶内容、设置访问权限、管理元数据等。
- 加密支持:允许对上传的数据进行加密,确保数据在传输和存储过程中的安全性。
- 命令行参数灵活:可以通过各种命令行参数来定制操作,例如指定存储桶区域、设置并发上传数量等。
- 性能表现:
- 中等数据量处理稳定:在处理一般规模的数据量时,表现较为稳定,不会出现明显的性能瓶颈。但对于大规模数据或大量小文件的操作,可能会显得有些吃力。
- 速度取决于网络和数据量:上传和下载速度受到网络带宽和数据量大小的影响。对于较小的文件,可能由于网络延迟等原因,速度相对较慢。
- 发展历程:
- 早期主流工具:s3cmd 是较早出现的 S3 命令行工具之一,在云计算发展初期就被广泛使用。
- 持续更新:随着 S3 服务的不断演进和用户需求的变化,s3cmd 也在不断进行更新和改进。增加了新的功能,修复了一些漏洞,以适应不断变化的环境。
- 适用场景:
- 个人用户和小型团队:对于个人用户或小型开发团队来说,s3cmd 是一个简单易用的工具,可以满足基本的 S3 存储管理需求。例如,备份个人文件、上传小型项目的资源等。
- 脚本化任务:可以在脚本中使用 s3cmd 命令,实现自动化的数据备份、文件传输等任务。对于一些简单的脚本化应用场景,s3cmd 是一个不错的选择。
2.2. 安装与配置
2.2.1. 安装
- Linux 和 Mac OS X
在 Linux 和 Mac OS X 上,可以使用包管理器来安装s3cmd。以下是在不同系统上的安装方法:
Ubuntu/Debian:
sudo apt-get install s3cmd
Fedora/CentOS/RHEL:
sudo yum install s3cmd
Mac OS X(使用 Homebrew):
brew install s3cmd
- Windows
在 Windows 上,可以通过 Cygwin 来安装s3cmd。以下是安装步骤:
- 下载并安装Cygwin。
- 在 Cygwin 安装过程中,选择安装
s3cmd包。
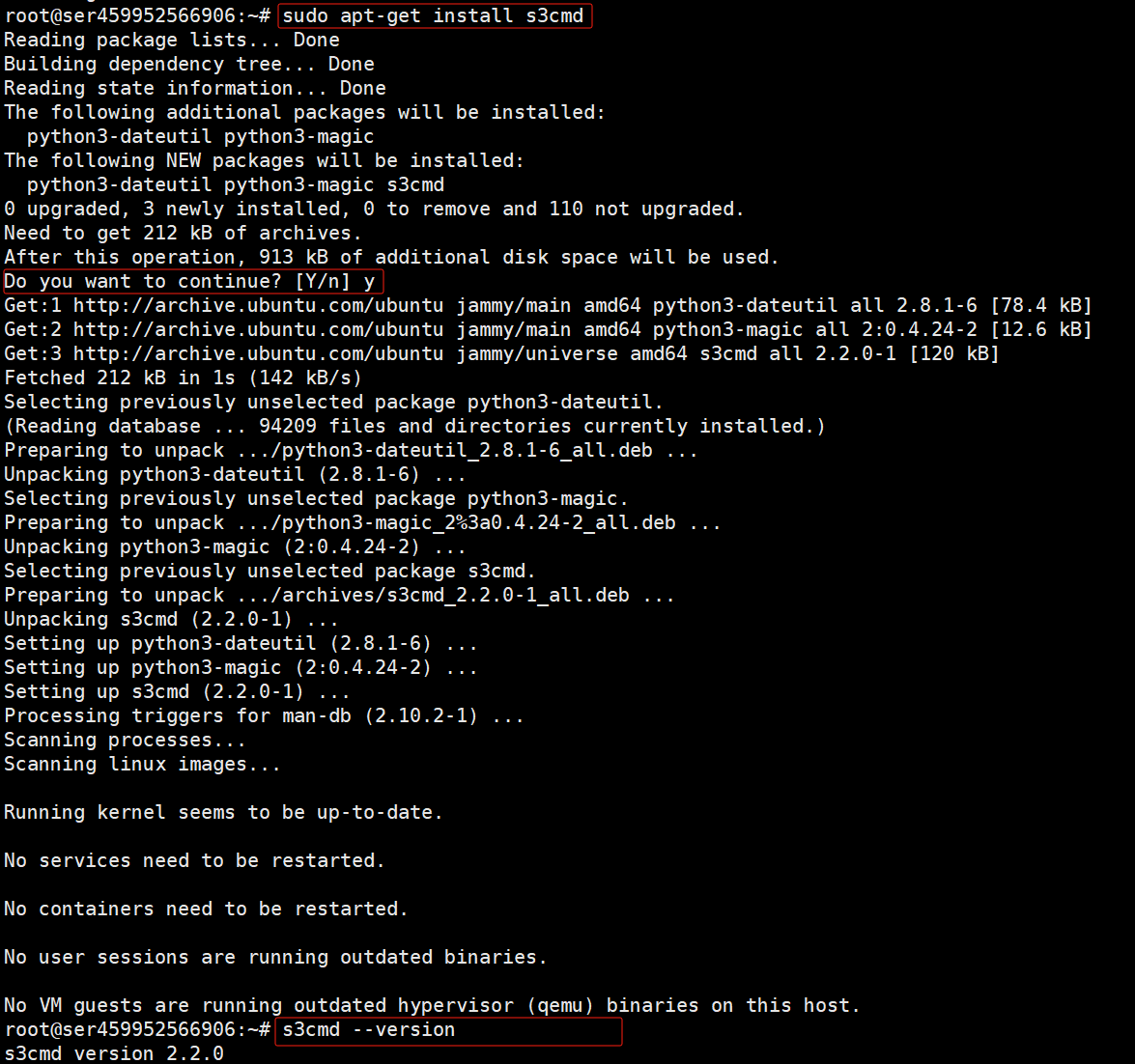
安装完成后,可以在命令提示符或终端中输入s3cmd --version来验证安装是否成功。
2.2.2. 配置
- 使用命令行
在使用s3cmd之前,需要进行一些配置。以下是配置步骤:
- 运行
s3cmd --configure命令。这将启动一个配置向导,询问你一些关于 S3 存储的信息。 - 输入你的 S3 访问密钥 ID 和秘密访问密钥。这些密钥可以在 S3 控制台的 “IAM 用户” 部分找到。
- 输入默认的 S3 存储桶区域。你可以在 S3 控制台的 S3 服务页面上找到存储桶所在的区域。
- 确认配置信息。配置向导将显示你输入的信息,让你确认是否正确。
- 测试配置。配置向导将尝试连接到 S3 存储,并列出你的存储桶。如果一切正常,你将看到存储桶的列表。
配置完成后,s3cmd将把配置信息保存在~/.s3cfg文件中。
你可以编辑这个文件来更改配置,或者使用s3cmd --configure命令重新运行配置向导。
这里用连接七牛云来举例,下面是使用命令行工具配置的详细记录,当前 s3cmd 的版本是 2.2.0 ,一行提示都没删:
root@ser459952566906:~# s3cmd --configure # 启动 s3cmd 配置过程,设置用于连接 S3 的参数
Enter new values or accept defaults in brackets with Enter.
Refer to user manual for detailed description of all options.
# 提示输入新值或按回车接受括号中的默认值,参考用户手册以了解每个选项的详细说明
Access key and Secret key are your identifiers for Amazon S3. Leave them empty for using the env variables.
# Access Key 和 Secret Key 是连接 Amazon S3 的唯一标识符。也可以留空并使用环境变量中已有的密钥
Access Key: gZFv***************ly_iAk
# 输入 Access Key,类似用户名的身份认证标识符
Secret Key: 3XHC***************6CJS9Mul
# 输入 Secret Key,类似密码的身份认证标识符
Default Region [US]: cn-south-1
# 输入默认区域(Region),如果服务位于特定区域,选择该区域以优化访问速度,此处选择“cn-south-1”(查看你的s3服务的信息)
Use "s3.amazonaws.com" for S3 Endpoint and not modify it to the target Amazon S3.
# 建议将 S3 Endpoint 设置为 “s3.amazonaws.com”,以便连接到 Amazon S3;若是其他兼容服务,则可指定不同的端点
S3 Endpoint [s3.amazonaws.com]: s3.cn-south-1.qiniucs.com
# 设置 S3 Endpoint,即目标服务的 API 地址;此处是七牛云的 S3 兼容端点
Use "%(bucket)s.s3.amazonaws.com" to the target Amazon S3. "%(bucket)s" and "%(location)s" vars can be used
if the target S3 system supports dns based buckets.
# 若目标 S3 系统支持基于 DNS 的桶访问方式,推荐使用 "%(bucket)s.s3.amazonaws.com";其中 "%(bucket)s" 表示桶名占位符
DNS-style bucket+hostname:port template for accessing a bucket [%(bucket)s.s3.amazonaws.com]: %(bucket)s.s3.cn-south-1.qiniucs.com
# 设置 DNS 样式的桶访问模板,指定每个桶的 DNS 结构;使用兼容端点配置,例如“%(bucket)s.s3.cn-south-1.qiniucs.com”
Encryption password is used to protect your files from reading
by unauthorized persons while in transfer to S3
# 可选:设置加密密码,在传输到 S3 时保护文件免受未授权人员读取
Encryption password:
# 输入加密密码(留空则不启用传输加密)
Path to GPG program [/usr/bin/gpg]:
# 设置 GPG 程序路径,GPG 用于加密传输数据,默认为“/usr/bin/gpg”
When using secure HTTPS protocol all communication with Amazon S3
servers is protected from 3rd party eavesdropping. This method is
slower than plain HTTP, and can only be proxied with Python 2.7 or newer
# 选择 HTTPS 协议可以保护与 S3 服务器的通信免受第三方监听,但可能比 HTTP 慢
Use HTTPS protocol [Yes]: yes
# 是否使用 HTTPS 协议,选择“yes”启用 HTTPS 以提高安全性
On some networks all internet access must go through a HTTP proxy.
Try setting it here if you can't connect to S3 directly
# 若网络要求所有访问通过 HTTP 代理服务器,可在此设置代理,以便连接 S3
HTTP Proxy server name:
# 输入 HTTP 代理服务器名称(留空则不使用代理)
New settings:
Access Key: gZFv***************_iAk
Secret Key: 3XHC***************JS9Mul
Default Region: cn-south-1
S3 Endpoint: s3.cn-south-1.qiniucs.com
DNS-style bucket+hostname:port template for accessing a bucket: %(bucket)s.s3.cn-south-1.qiniucs.com
Encryption password:
Path to GPG program: /usr/bin/gpg
Use HTTPS protocol: True
HTTP Proxy server name:
HTTP Proxy server port: 0
# 显示新配置内容,包括密钥、区域、端点、桶访问模板、加密密码、GPG 程序路径、是否启用 HTTPS 和代理服务器信息
Test access with supplied credentials? [Y/n] y
# 测试是否可以使用配置的密钥访问存储服务,选择“y”以验证
Please wait, attempting to list all buckets...
# 提示稍候,正在尝试列出所有桶以验证访问权限
Success. Your access key and secret key worked fine :-)
# 若测试成功,将显示访问密钥验证成功的提示
Now verifying that encryption works...
# 接下来验证加密功能
Not configured. Never mind.
# 如果未配置加密功能,会提示忽略该项
Save settings? [y/N] y
# 保存配置文件以便后续操作,选择“y”确认保存
Configuration saved to '/root/.s3cfg'
# 配置已保存到 “/root/.s3cfg” 文件,用于后续 s3cmd 命令自动读取
如上就完成了配置;
- 手动创建配置文件配置
如果你先命令行配置麻烦,你可以直接根目录创建一个 .s3cfg 文件;
nano ~/.s3cfg
然后复制下面信息进去并替换为你的 S3 服务的信息,下面这是配置 Cloudflare R2 的样例1:
[default]
access_key = <your-access-key-id>
secret_key = <your-secret-access-key>
bucket_location = auto
host_base = <account-id>.r2.cloudflarestorage.com
host_bucket = <account-id>.r2.cloudflarestorage.com
enable_multipart = False
account-id 很多地方都能获取:

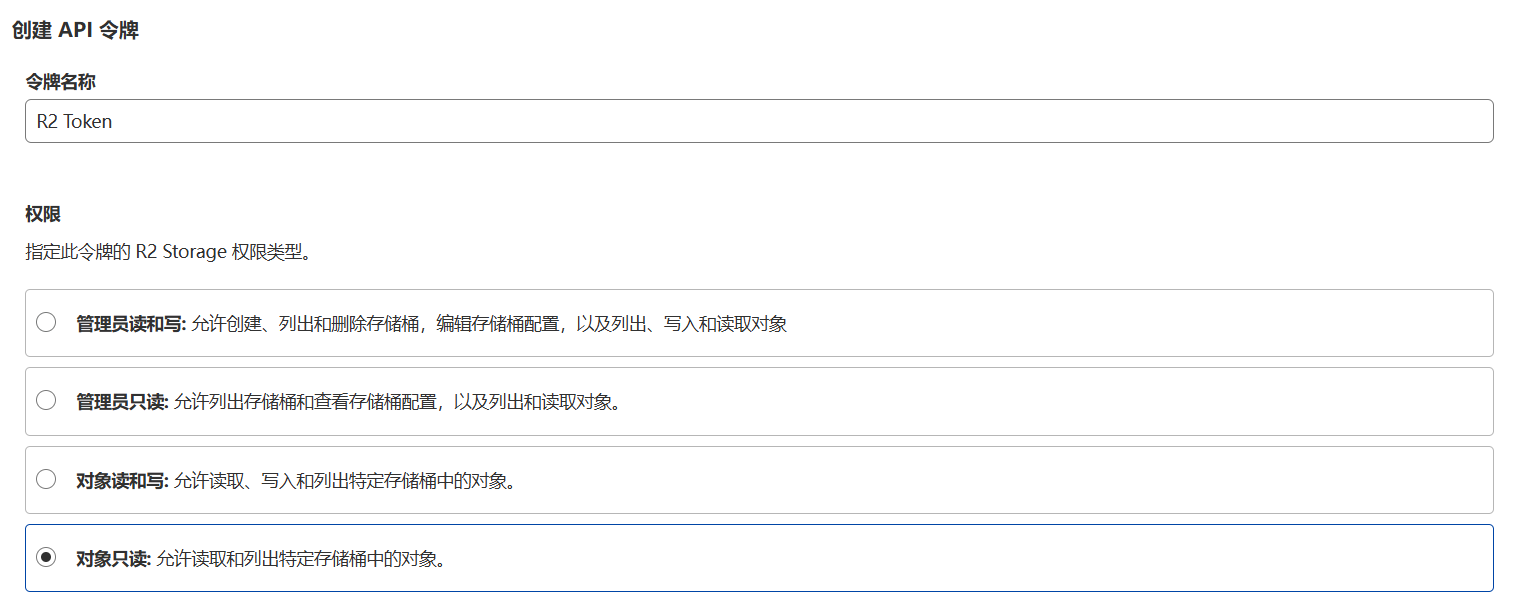
如果是 R2,令牌创建的时候也要注意,权限不对的话,会报错:
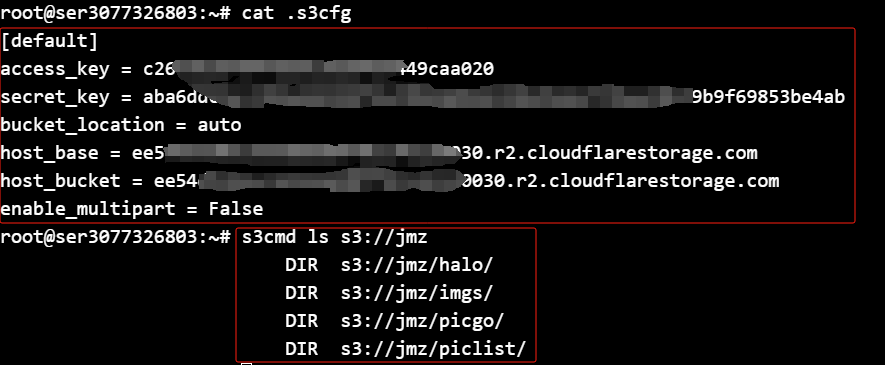
我配置的如下:
2.3. 使用指南2
详细内容参考官网问答:https://s3tools.org/usage
2.3.1. 基础操作
-
查看桶:
s3cmd ls -
查看桶里文件:
s3cmd ls s3://my-bucket -
创建 Bucket:
s3cmd mb s3://my-bucket -
上传文件:
s3cmd put localfile.txt s3://my-bucket -
下载文件:
s3cmd get s3://my-bucket/yourfile.txt -
删除文件:
s3cmd del s3://my-bucket/yourfile.txt
2.3.2. s3cmd 进阶用法
以下是 s3cmd 的进阶用法,详细讲解如何进行本地同步、权限管理、自动化备份等操作。
1. 双向同步:同步到 S3 和从 S3 同步到本地
s3cmd 不仅可以将本地文件夹同步到 S3,还可以将 S3 内容同步到本地。
-
本地文件夹同步到 S3:
s3cmd sync /local-folder/ s3://my-bucket -
从 S3 同步到本地:
s3cmd sync s3://my-bucket /local-folder/使用
--delete-removed参数确保同步过程中删除本地不需要的文件:s3cmd sync s3://my-bucket /local-folder/ --delete-removed
2. 设置文件和 Bucket 的权限
s3cmd 允许我们为文件和 Bucket 设置权限,通过 setacl 命令可以实现控制:
-
设置文件为公开访问:
s3cmd setacl s3://my-bucket/myfile.txt --acl-public -
设置文件为私有:
s3cmd setacl s3://my-bucket/myfile.txt --acl-private
3. 使用 cron 实现自动化备份
s3cmd 支持与 cron 作业结合,便于自动化管理 S3 文件,例如定时同步本地文件夹到 S3,实现自动备份。
设置方法:
-
打开
cron编辑器:crontab -e -
在
cron编辑器中添加以下作业,将/local-folder/文件夹同步到s3://my-bucket,每天凌晨 2 点执行:0 2 * * * s3cmd sync /local-folder/ s3://my-bucket --delete-removed时间格式
0 2 \* \* \*:这是cron的时间格式,表示任务每天凌晨 2 点运行一次。每个字段的含义为:0:分钟,表示 0 分钟,即整点。2:小时,表示凌晨 2 点。* * *:依次表示日、月、星期,这里使用*表示任何值,即每天、每月、每周都执行。
s3cmd sync /local-folder/ s3://my-bucket --delete-removed:这是s3cmd的同步命令。sync:s3cmd的同步命令,用于将本地文件夹与 S3 存储桶内容保持一致。/local-folder/:本地源文件夹路径。将该文件夹的内容同步到 S3。s3://my-bucket:S3 目标路径,表示目标存储桶my-bucket。--delete-removed:启用此选项后,如果本地文件夹中删除了文件,这些删除也会同步到 S3(即从 S3 中删除对应文件),确保 S3 存储的内容与本地一致。
保存并退出。此时
cron会按照设定时间自动执行备份任务。如果你用了
1Panel的话,可以使用计划任务很好的解决这个问题: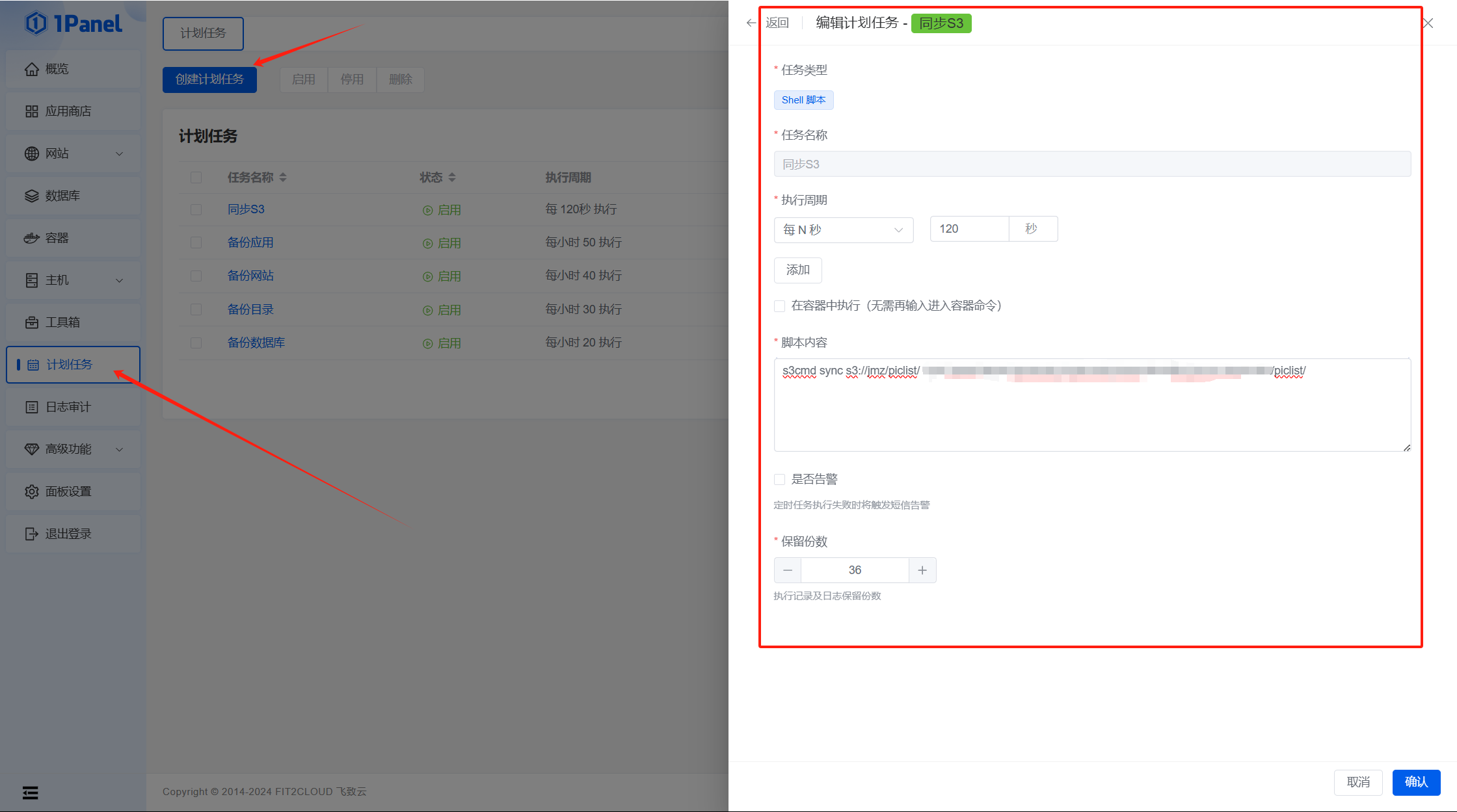
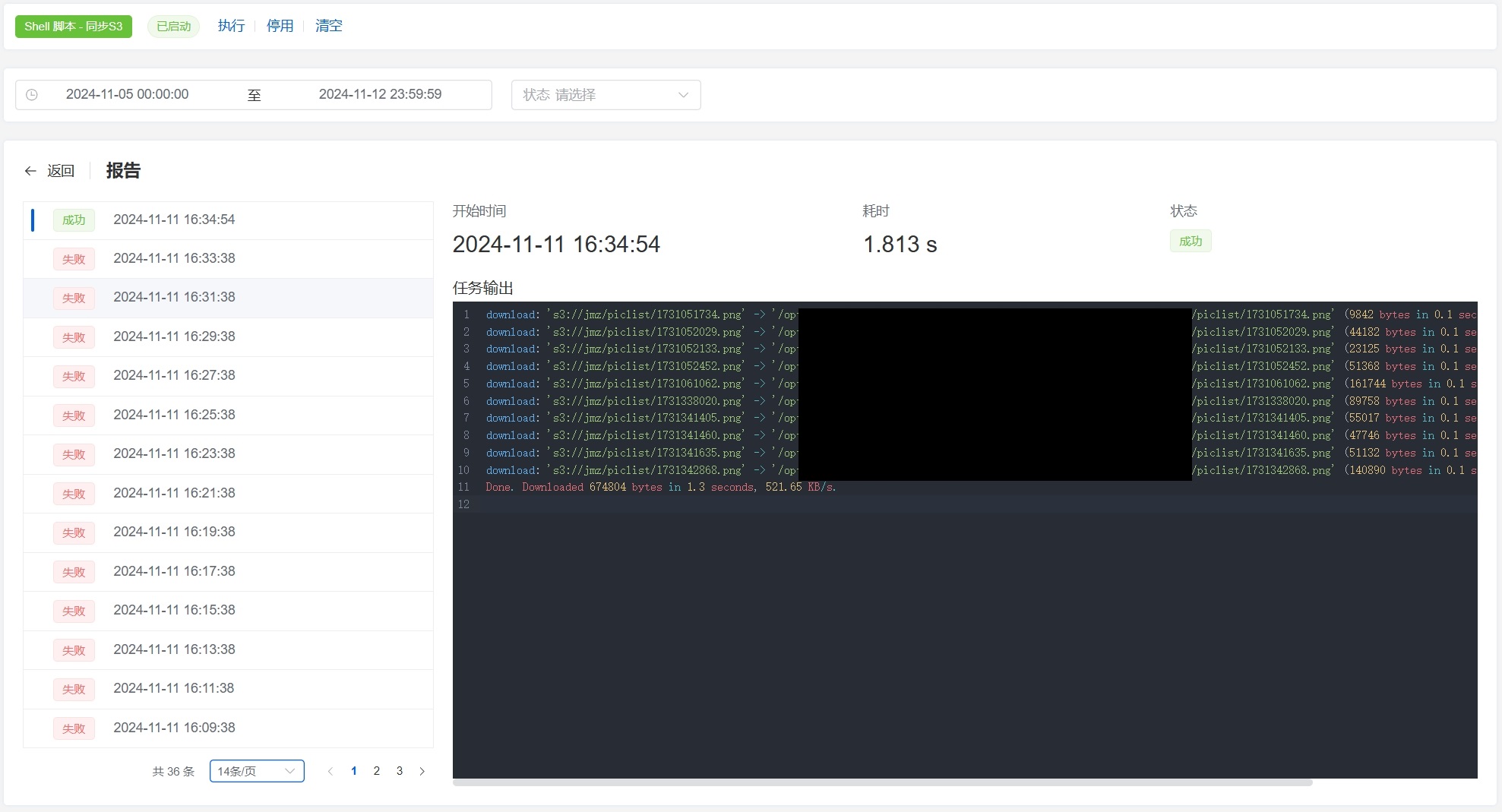
4. 数据加密
s3cmd 可以加密文件后再上传到 S3,确保数据安全。使用 --encrypt 选项可自动加密:
s3cmd put --encrypt localfile.txt s3://my-bucket
若要从 S3 下载加密的文件,s3cmd 会自动解密文件,但需要在配置中设置密钥。
5. 文件版本控制
如果 S3 Bucket 启用了版本控制,s3cmd 支持查看文件的不同版本。
-
列出文件的所有版本:
s3cmd ls --versions s3://my-bucket/myfile.txt -
删除特定版本:
s3cmd del s3://my-bucket/myfile.txt --version-id VERSION_ID
6. 分段上传大文件
对于大文件,s3cmd 支持分段上传,通过 --multipart-chunk-size-mb 设置分段大小:
s3cmd put --multipart-chunk-size-mb=100 largefile.zip s3://my-bucket
7. 批量操作
支持使用通配符批量上传或删除文件。例如,上传当前文件夹下所有 .txt 文件:
s3cmd put *.txt s3://my-bucket
3. S5cmd使用教程
3.1. 简介3
GitHub 地址:https://github.com/peak/s5cmd

s5cmd 是一个针对 Amazon S3 和类似对象存储服务设计的超快速命令行工具,支持批量文件操作和通配符管理功能,能够极大地优化和简化大量文件的对象存储操作流程。与其他常见工具(如 aws-cli 和 s3cmd)相比,s5cmd 的速度优势尤为突出,特别是在处理大规模文件上传和下载时更显得高效。
- 功能特点:
- 高效操作命令:提供高效的 S3 操作命令,旨在提高数据传输和操作的效率。可能具有一些独特的功能,如快速上传和下载、批量操作等。
- 注重性能和易用性:在设计上注重性能和易用性,让用户能够快速上手并高效地使用。
- 命令行参数丰富:可以通过各种命令行参数来定制操作,满足不同用户的需求。
- 制表符自动补全:s5cmd 支持命令和文件路径的自动补全功能,提升用户体验,减少输入错误,并加快操作速度。
- 性能表现:
- 高性能数据传输:在某些方面可能比其他工具表现更出色,具体取决于使用场景。对于大规模数据传输和操作有较好的优化,能够快速完成任务。根据 Joshua Robinson 的测试,s5cmd 的性能远超同类工具。具体表现为:
- 在文件上传方面,s5cmd 比
s3cmd快 32 倍,比aws-cli快 12 倍。 - 在文件下载方面,s5cmd 能够充分利用 40Gbps 带宽(相当于 ~4.3 GB/s),而
s3cmd和aws-cli分别只能达到 85 MB/s 和 375 MB/s。
- 在文件上传方面,s5cmd 比
- 适应不同数据规模:无论是处理小文件还是大规模数据,都能保持较高的性能。可以根据数据量的大小自动调整传输策略,提高效率。
- 低系统资源占用:s5cmd 在设计时就注重资源利用效率,因此它在执行文件操作时对系统资源的占用非常低,适合长时间批量处理任务。
- 高性能数据传输:在某些方面可能比其他工具表现更出色,具体取决于使用场景。对于大规模数据传输和操作有较好的优化,能够快速完成任务。根据 Joshua Robinson 的测试,s5cmd 的性能远超同类工具。具体表现为:
- 发展历程:
- 新兴工具的崛起:作为一种新的 S3 命令行工具出现,不断发展以满足用户需求。在性能和功能上不断进行改进和优化,以吸引更多用户。
- 社区反馈推动发展:通过用户的反馈和建议,不断改进工具的性能和功能。社区的参与对于 s5cmd 的发展起到了重要的推动作用。
- 适用场景:
- 对性能要求较高的任务:适用于对性能要求较高的 S3 存储管理任务,如大规模数据备份、迁移等。可以快速完成数据传输和操作,提高工作效率。
- 自动化脚本和批量操作:可以在自动化脚本中使用 s5cmd 命令,实现批量上传、下载、删除等操作。对于需要处理大量数据的场景,非常有用。
3.2. 安装与配置
s5cmd 提供了跨平台支持,可在多种操作系统中安装,以下是 Linux 安装步骤,其他系统的安装请查阅官方文档:
3.2.1. 下载预编译的二进制文件
首先,需要下载适用于 Linux 的 s5cmd 二进制文件,下载地址为https://github.com/peak/s5cmd/releases,它提供了很多版本,你不知道怎么选的话选下看:
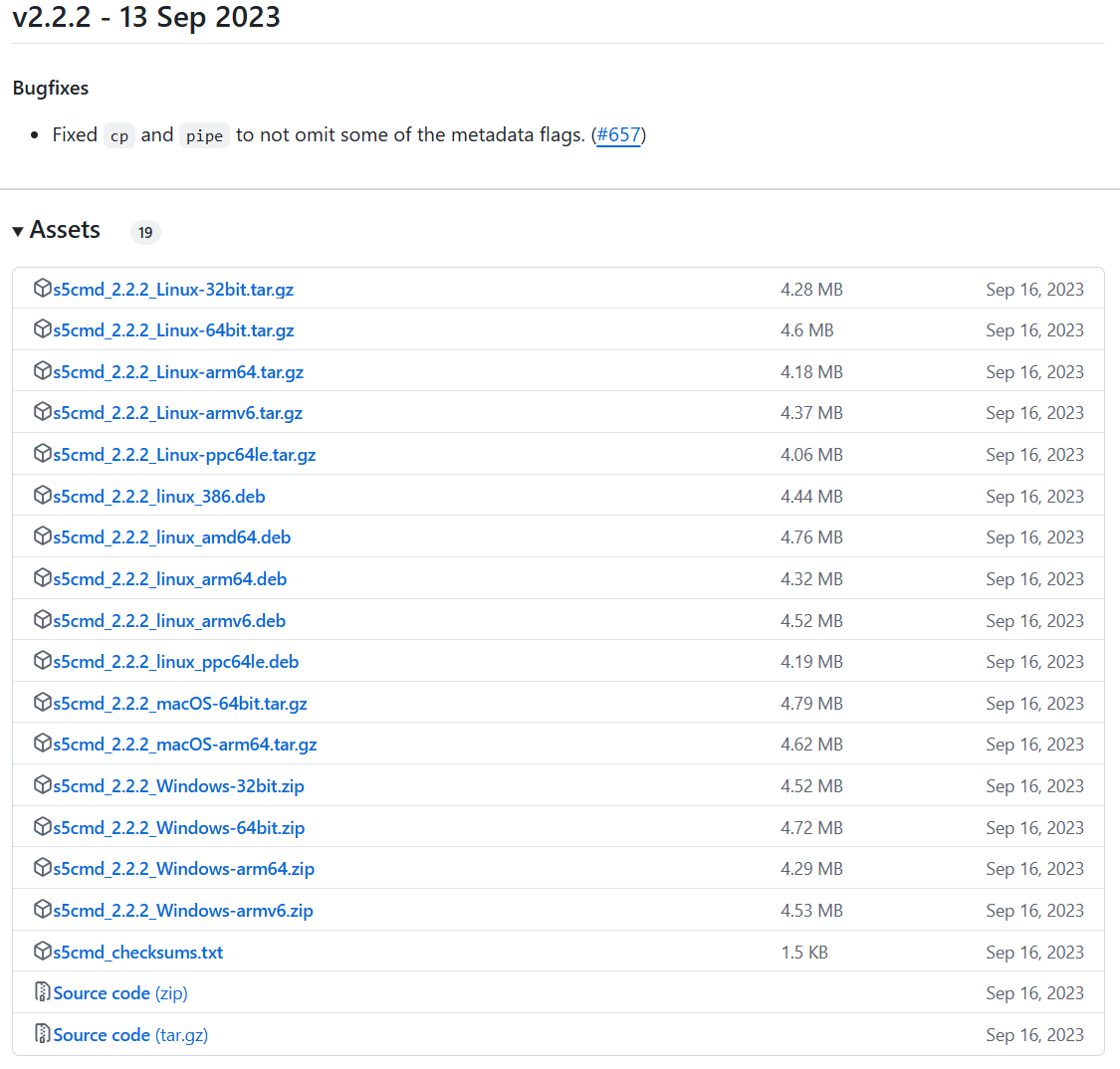
3.2.2. 安装包选择
tar.gz 文件是压缩的安装包,适合需要手动解压和安装的用户:
- Linux 32-bit:
- 文件:
s5cmd_2.2.2_Linux-32bit.tar.gz - 适用于 32 位的 Linux 系统。如果你的系统是 32 位,这个文件适用。
- 文件:
- Linux 64-bit:
- 文件:
s5cmd_2.2.2_Linux-64bit.tar.gz - 适用于 64 位的 Linux 系统。如果你的系统是 64 位,这个文件适用。
- 文件:
- Linux ARM 64-bit:
- 文件:
s5cmd_2.2.2_Linux-arm64.tar.gz - 适用于 ARM 架构的 64 位系统(如 Raspberry Pi 4 或其他 ARM64 设备)。
- 文件:
- Linux ARM v6:
- 文件:
s5cmd_2.2.2_Linux-armv6.tar.gz - 适用于较老的 ARM 设备,特别是低性能的 ARMv6 系统。
- 文件:
- Linux ppc64le:
- 文件:
s5cmd_2.2.2_Linux-ppc64le.tar.gz - 适用于基于 PowerPC 架构的 Linux 系统。
- 文件:
如果你使用的是基于 Debian 的 Linux 发行版(如 Ubuntu、Debian、Linux Mint 等),你可以使用 .deb 文件直接通过包管理器安装:
- Linux 386 (32-bit):
- 文件:
s5cmd_2.2.2_linux_386.deb - 适用于 32 位的 Debian/Ubuntu 系统。
- 文件:
- Linux AMD64 (64-bit):
- 文件:
s5cmd_2.2.2_linux_amd64.deb - 适用于 64 位的 Debian/Ubuntu 系统。
- 文件:
- Linux ARM 64-bit:
- 文件:
s5cmd_2.2.2_linux_arm64.deb - 适用于 ARM 架构的 64 位 Debian/Ubuntu 系统。
- 文件:
- Linux ARM v6:
- 文件:
s5cmd_2.2.2_linux_armv6.deb - 适用于较老的 ARMv6 架构系统(例如 Raspberry Pi 1 和 2)。
- 文件:
- Linux ppc64le:
- 文件:
s5cmd_2.2.2_linux_ppc64le.deb - 适用于基于 PowerPC 的 Debian/Ubuntu 系统。
- 文件:
对于 Linux 系统,你可以通过以下命令来检查系统架构:
uname -m
- 如果输出是
x86_64,则说明你使用的是 64 位系统。 - 如果输出是
i686或i386,则说明你使用的是 32 位系统。 - 如果输出是
aarch64,则说明你使用的是 64 位 ARM 系统。 - 如果输出是
armv6或类似标识,则是 ARMv6 架构。
例如:

我就需要选择:s5cmd_2.2.2_Linux-64bit.tar.gz
3.2.3. 开始安装
安装包下载的方式很多,你可以下载到本地上传,也可以直接运行下面的命令(文件地址你需要在https://github.com/peak/s5cmd/releases里面复制):
wget https://github.com/peak/s5cmd/releases/download/v2.2.2/s5cmd_2.2.2_Linux-64bit.tar.gz
下载后,解压文件:
tar -xvzf xxxxxxx.tar.gz
为了在任何地方使用 s5cmd,将其移动到 /usr/local/bin 目录:
sudo mv s5cmd /usr/local/bin/
运行以下命令查看 s5cmd 版本,确保安装成功:
s5cmd version
3.2.4. 配置 S3 凭证
和 s3cmd 类似,需要配置一下连接信息,但是它没 s3cmd 那么方便;
-
使用AWS CLI 配置凭证
如果没有安装 AWS CLI,可以先安装它。使用以下命令在不同操作系统上安装 AWS CLI:
- Linux/MacOS:使用
brew install awscli或下载并安装官方版本。 - Windows:从 AWS CLI 官方下载页面 下载并安装。
配置 AWS 凭证:
aws configure系统会提示输入 Access Key ID、Secret Access Key、默认区域和输出格式。根据实际情况填写。
- Linux/MacOS:使用
-
使用环境变量配置
通过设置环境变量配置的话,运行下面的命令配置环境变量即可:
export AWS_ACCESS_KEY_ID=your_access_key_id export AWS_SECRET_ACCESS_KEY=your_secret_access_key export AWS_DEFAULT_REGION=auto然后,注意连接的时候需要使用
--endpoint-url参数允指定自定义的 S3 端点 URL:例如:
s5cmd --endpoint-url https://<account-id>.r2.cloudflarestorage.com ls
- 使用配置文件配置凭证
mkdir -p ~/.aws接下来,使用文本编辑器(如
nano)打开或创建~/.aws/credentials文件:nano ~/.aws/credentials在
credentials文件中,可以按以下格式添加凭证:[default] aws_access_key_id = YOUR_ACCESS_KEY_ID aws_secret_access_key = YOUR_SECRET_ACCESS_KEY [profile_name] aws_access_key_id = YOUR_ACCESS_KEY_ID aws_secret_access_key = YOUR_SECRET_ACCESS_KEY
[default]是默认配置文件的名称,如果你没有指定 profile,AWS CLI 会使用它。
[profile_name]是你为特定配置创建的命名配置文件,替换profile_name为你自己定义的名称。在
nano中,按Ctrl + O保存文件,然后按Enter确认保存。接着按Ctrl + X退出编辑器。然后同样的方法,在
~/.aws/config文件中,为配置文件指定 S3 兼容服务的端点:[default] region = us-east-1配置文件怎么写:配置 AWS CLI
这里还有个知识点,上面的
credentials中不是配置了两个信息嘛,代表你可以设置多个连接信息,怎么切换呢?直接在命令行中使用--profile指定即可;例如:s5cmd --profile profile_name --endpoint-url https://<your-endpoint>.r2.cloudflarestorage.com ls
- 使用
s5cmd命令行参数传递凭证
s5cmd --access-key “your_access_key_id” --secret-key “your_secret_access_key” --region auto --endpoint-url https://xxx.r2.cloudflarestorage.com ls s3://your-bucket-name/
3.3. 使用指南
详细信息参考:https://github.com/peak/s5cmd/blob/master/README.md
3.3.1. 基础操作
- 列出 S3 存储桶和对象
s5cmd ls 命令用于列出指定 S3 存储桶中的内容。可以按需列出不同层级的文件对象。
s5cmd ls s3://mybucket/
使用通配符,还可以列出特定前缀或文件类型的对象:
s5cmd ls s3://mybucket/logs/*.txt
- 单文件上传与下载操作
上传文件到 S3:
s5cmd cp myfile.txt s3://mybucket/
下载文件到本地:
s5cmd cp s3://mybucket/myfile.txt ./
- 文件/文件夹删除
删除单个文件:
s5cmd rm s3://mybucket/myfile.txt
批量删除特定前缀的文件(例如删除所有 .log 文件):
s5cmd rm s3://mybucket/logs/*.log
- 查看文件信息
s5cmd stat 命令可用于查看指定文件的元数据,包括文件大小、创建时间等。
s5cmd stat s3://mybucket/myfile.txt
- 对象复制操作
s5cmd 支持在同一存储桶内或不同存储桶之间复制文件。
在同一存储桶内复制:
s5cmd cp s3://mybucket/myfile.txt s3://mybucket/mycopy.txt
在不同存储桶之间复制:
s5cmd cp s3://source-bucket/myfile.txt s3://destination-bucket/myfile.txt
3.3.2. s5cmd 进阶功能
- 批量上传与下载
利用通配符,s5cmd 可以一次性处理多个文件或文件夹。
批量上传:
s5cmd cp localdir/*.txt s3://mybucket/
批量下载:
s5cmd cp s3://mybucket/data/* ./localdir/
- 本地与 S3 的双向同步
s5cmd sync 命令可以实现本地目录与 S3 之间的单向或双向同步。
单向同步(本地到 S3):
s5cmd sync ./localdir/ s3://mybucket/
单向同步(S3 到本地):
s5cmd sync s3://mybucket/ ./localdir/
- 并发操作
s5cmd 支持通过调整并发参数加快传输速度,尤其在大文件或大量文件传输时表现更佳。
s5cmd cp -c 10 localdir/*.txt s3://mybucket/
其中 -c 10 表示设置并发数为 10。
- 重试策略与超时设置
通过指定重试次数与超时,可以提高传输的稳定性,避免长时间卡顿或因网络问题中断传输。
s5cmd cp --retry 3 --timeout 60s localfile.txt s3://mybucket/
- 文件夹移动操作
s5cmd 支持文件夹的移动,可在同一区域或不同区域间完成:
s5cmd mv s3://source-bucket/folder s3://destination-bucket/folder
- 数据压缩与解压
可以直接将压缩文件上传至 S3,或下载后自动解压:
s5cmd cp myfile.zip s3://mybucket/
# 或从 S3 下载并解压
s5cmd cp s3://mybucket/myfile.zip ./
unzip myfile.zip
4. 其他替代工具
4.1. s4cmd
GitHub地址:https://github.com/bloomreach/s4cmd

s4cmd 是一个为处理海量数据而生的 S3 存储命令行工具。它专门设计用于高并发场景,能够在传输大文件和大量小文件时显著加速。相比 AWS CLI,s4cmd 更偏重于效率和性能,支持多线程和增量同步,让大规模数据上传或下载变得更加快捷可靠,是处理 S3 数据的理想选择。
- 功能特点:
- 性能优化:受 s3cmd 启发,但在性能方面进行了大量优化。尤其在处理大文件和大量数据时,表现出更高的效率。
- 额外功能和修复:针对一些特定的使用需求,添加了额外的功能。同时,修复了 s3cmd 中存在的一些问题,提高了工具的稳定性和可靠性。
- 兼容性考虑:努力兼容 s3cmd 的最常见使用场景,但由于一些改进和修复,不完全是即插即用的兼容性。在某些情况下,可能需要对现有脚本进行一些调整。
- 性能表现:
- 大文件传输优势明显:在处理大文件时,s4cmd 能够充分利用网络带宽,提高传输速度。相比 s3cmd,在处理大文件和大规模数据时性能有显著提升。
- 高效的并发处理:支持并发上传和下载,可以同时处理多个文件,提高整体操作效率。
- 发展历程:
- 源于需求改进:由于在使用 s3cmd 过程中发现了一些性能和功能上的不足,开发者创建了 s4cmd。旨在提供一个更强大、更高效的 S3 命令行工具。
- 不断演进:随着用户的反馈和实际使用场景的需求,s4cmd 也在不断发展和完善。添加新的功能,优化性能,以更好地满足用户的需求。
- 适用场景:
- 大规模数据处理:适用于需要处理大量数据或大文件的场景,如数据备份、大规模文件传输等。对于对性能要求较高的企业用户和大规模数据处理任务,s4cmd 是一个不错的选择。
- 复杂脚本化应用:对于复杂的脚本化应用程序,s4cmd 的性能优势和额外功能可以提高脚本的执行效率和稳定性。
4.2. aws-cli
GitHub地址:https://github.com/aws/aws-cli
官网:什么是 AWS Command Line Interface?

AWS CLI 是亚马逊官方推出的一款命令行工具,提供了几乎所有 AWS 服务的管理能力。从 S3 文件管理到启动 EC2 实例,再到配置 IAM 用户,只需一条命令就能轻松实现。它是云开发者的必备利器,不仅跨平台,而且支持脚本化操作,让你以最快速的方式管理 AWS 资源。
- 功能特点:
- 开源且广泛支持:作为开源工具,由 AWS 官方维护,得到了广泛的社区支持。可以与多种 AWS 服务进行交互,不仅仅局限于 S3。
- 多平台适用:支持在不同的操作系统和环境中使用,包括 Linux、Windows 和远程终端。可以在本地命令行、远程服务器、EC2 实例等多种环境中运行。
- 与管理控制台功能一致:提供与 AWS Management Console 相同的功能,可通过命令行实现基础设施即服务(IaaS)的管理和访问。方便用户在不使用图形界面的情况下进行云资源管理。
- 自定义命令简化复杂服务:对于一些复杂的 AWS 服务,提供了自定义命令,可以简化使用过程。例如,对于 AWS Lambda、AWS CloudFormation 等服务,有专门的命令来方便用户进行操作。
- 性能表现:
- 稳定可靠:由 AWS 官方维护,性能稳定可靠。在处理大规模的 AWS 资源管理时,表现出色。能够快速响应命令,执行各种操作。
- 优化的网络传输:利用 AWS 的网络基础设施,进行优化的网络传输。在上传和下载数据时,能够充分利用 AWS 的全球网络,提高速度和效率。
- 发展历程:
- 随着 AWS 服务发展:随着 AWS 服务的不断发展和壮大,aws-cli 也在不断更新和扩展。新增了对新服务的支持,改进了现有功能,以满足用户不断变化的需求。
- 社区贡献推动:由于是开源工具,得到了广大开发者的贡献和支持。社区不断提出改进建议和新功能需求,推动了 aws-cli 的发展。
- 适用场景:
- AWS 用户的首选工具:对于使用 AWS 服务的企业和开发者来说,aws-cli 是一个必不可少的工具。可以方便地管理和操作各种 AWS 资源,实现自动化部署、资源监控等任务。
- 大规模云资源管理:适用于需要进行大规模云资源管理和自动化脚本编写的场景。可以通过编写脚本,实现批量操作、定时任务等功能,提高工作效率。
4.3. goofys
GitHub地址:https://github.com/kahing/goofys

Goofys 是一个让 S3 像本地文件系统一样挂载的工具。通过它,你可以直接访问 S3 上的文件,就像在本地硬盘上一样操作,不需要下载或同步。Goofys 不仅省去了繁琐的下载步骤,还优化了常见的读写操作,是在轻量数据访问场景下使用 S3 的高效选择,尤其适合日志分析和数据备份等需求。
- 功能特点:
- S3 存储桶挂载为文件系统:允许将 S3 存储桶挂载为文件系统,使用户可以像操作本地文件系统一样操作 S3 存储桶中的数据。
- 性能优先,POSIX 标准次之:强调性能优先,因此在一些方面可能不完全符合 POSIX 文件系统标准。例如,随机写入可能会失败,没有每个文件的权限控制等。
- 无磁盘数据缓存:没有磁盘数据缓存,这意味着每次访问文件都需要从 S3 存储桶中获取数据。虽然这可能会影响一些性能,但也确保了数据的一致性。
- 接近打开状态的一致性模型:一致性模型接近打开状态,这意味着在写入数据后,可能需要一段时间才能在其他地方看到最新的数据。
- 性能表现:
- 读取性能较好:对于读取操作,性能较好,尤其是对于顺序读取。可以快速获取大量数据,适用于一些数据处理和分析场景。
- 写入性能受限:由于没有磁盘数据缓存,写入操作可能相对较慢。此外,随机写入可能会失败,这也限制了在某些场景下的使用。
- 发展历程:
- 特定需求驱动:为了满足特定的文件系统挂载需求而开发。在一些需要将 S3 存储桶作为文件系统使用的场景中,goofys 提供了一种方便的解决方案。
- 不断改进性能和稳定性:随着用户的使用和反馈,不断改进性能和稳定性。优化读取和写入操作,提高工具的可靠性。
- 适用场景:
- 开发环境和数据分析:适用于一些开发环境中,需要将 S3 存储桶作为文件系统来使用。例如,在进行数据分析时,可以将数据存储在 S3 中,然后通过 goofys 挂载到本地进行处理。
- 对随机写入要求不高的场景:对于对随机写入要求不高的应用程序,可以考虑使用 goofys。例如,一些数据备份和归档场景,主要是进行顺序写入操作。
4.4. 性能比对
这部分内容来源于S5cmd for High Performance Object Storage:
- 大对象性能
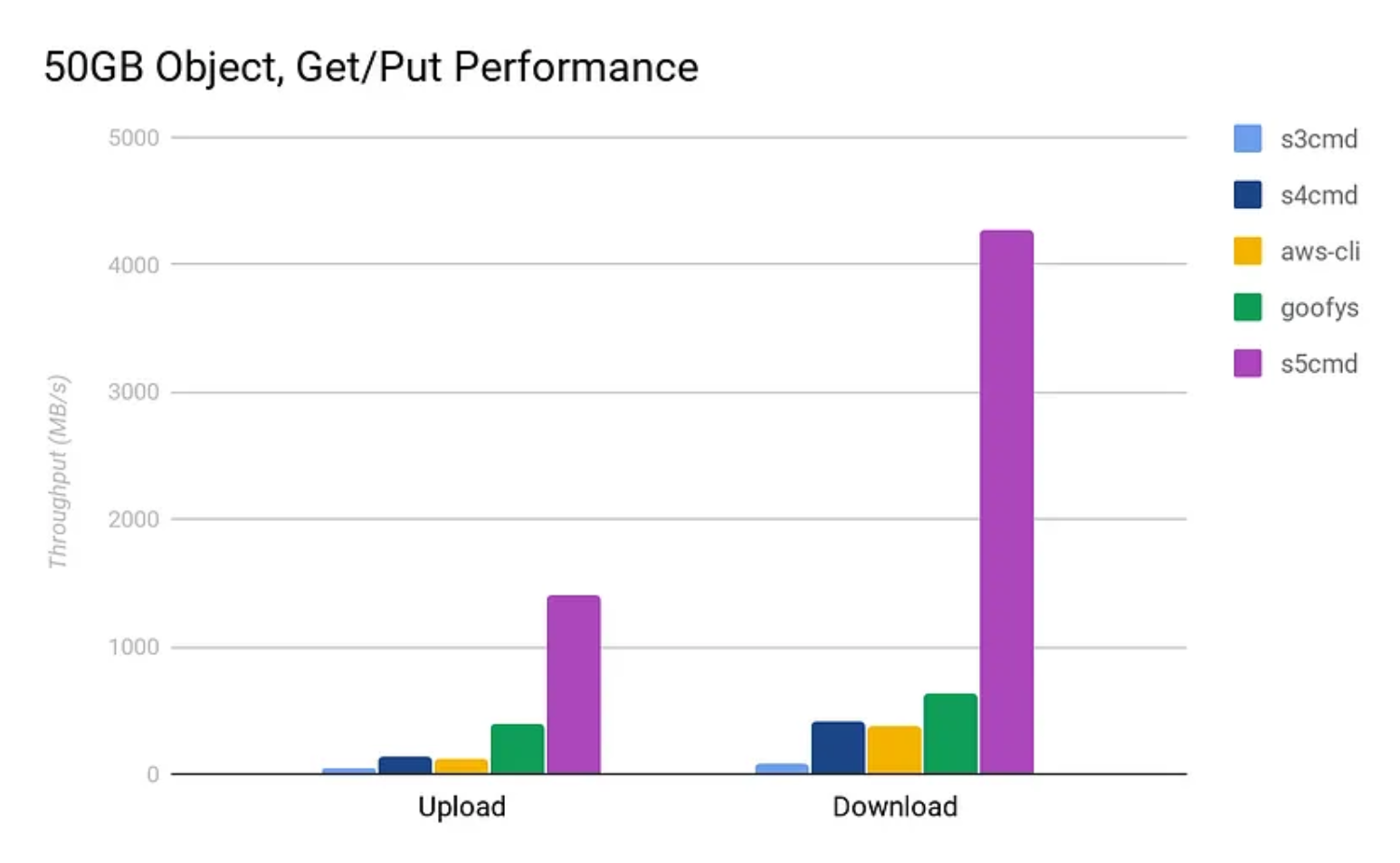
- 小对象性能
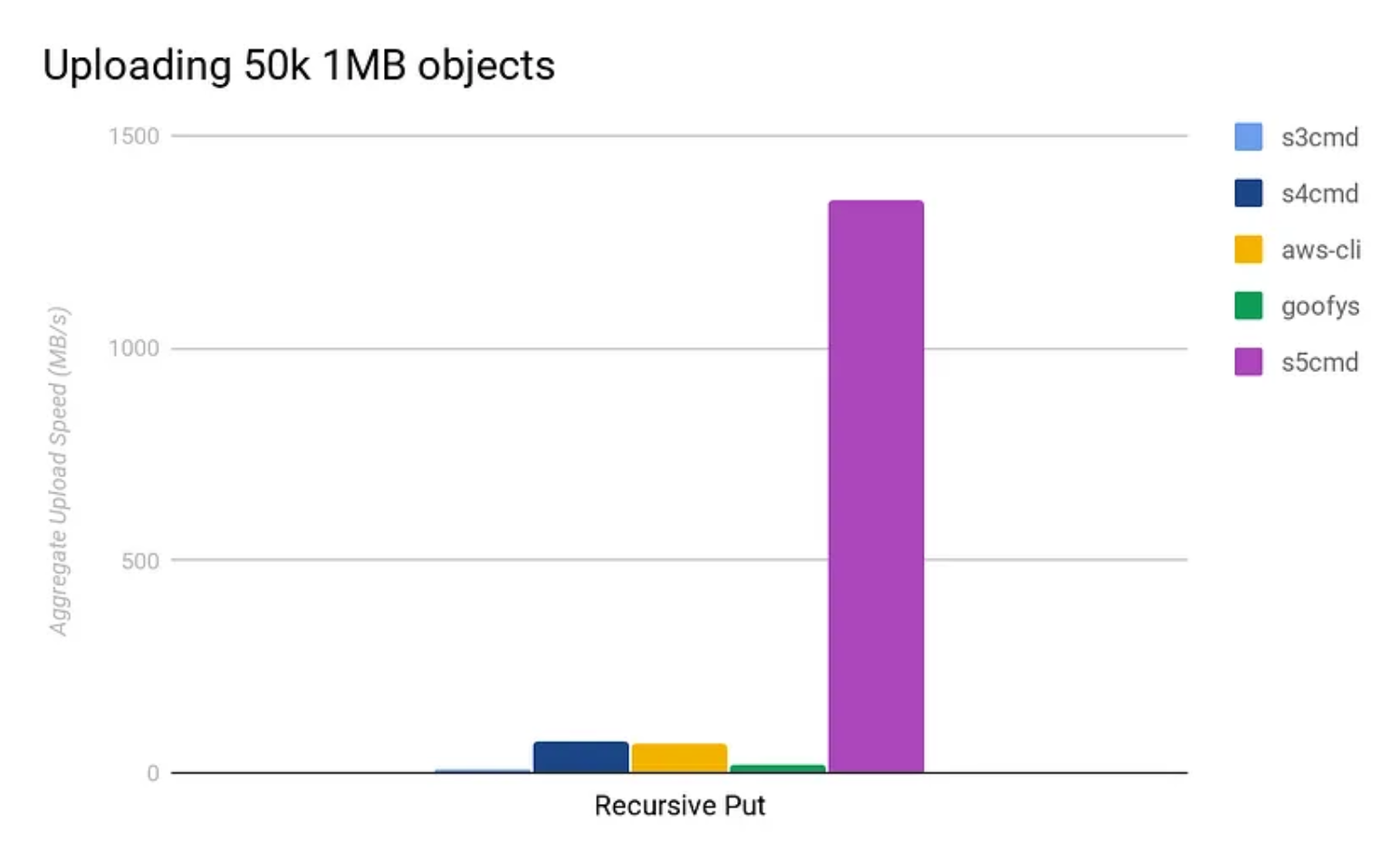
- 在aws中的性能
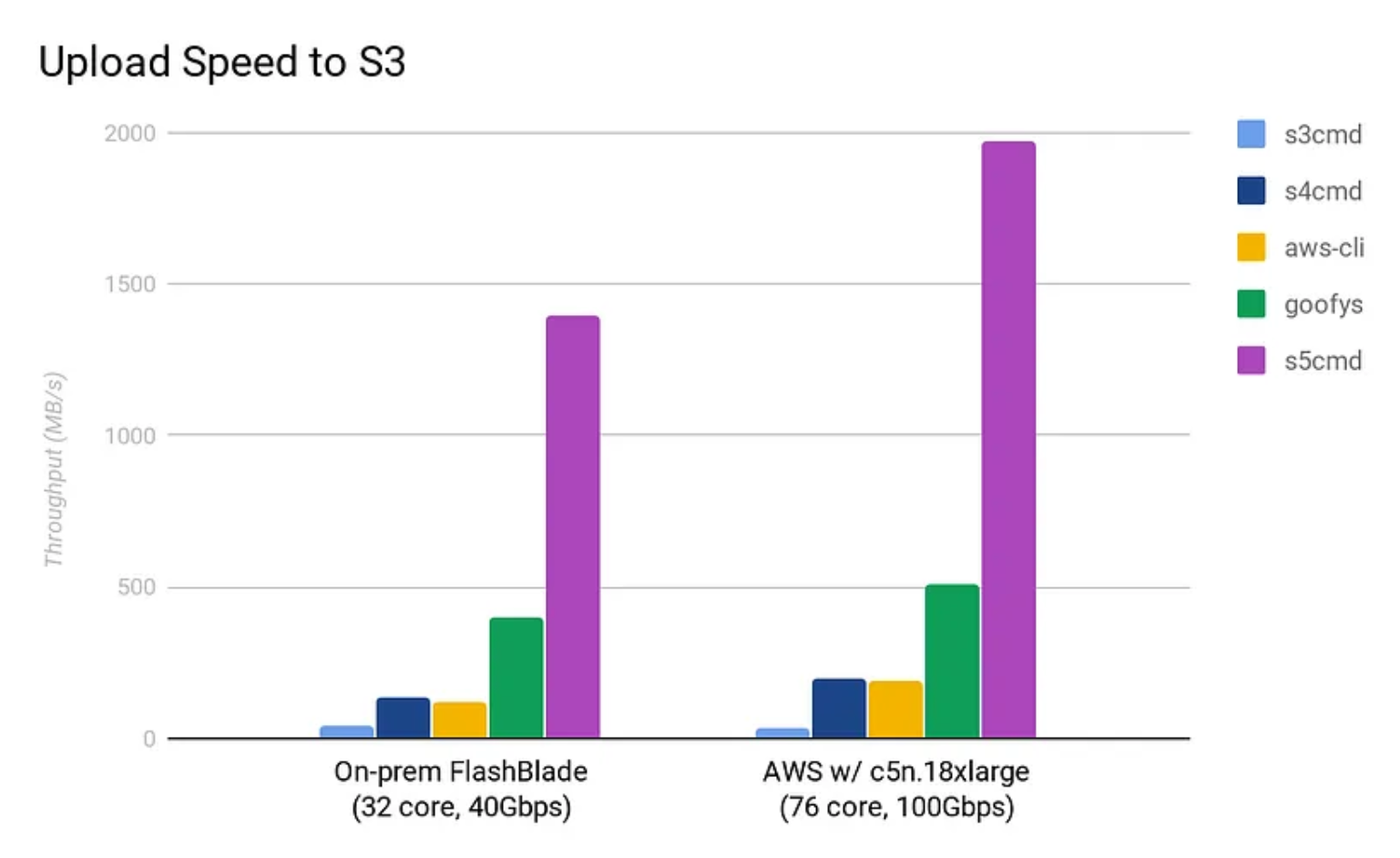
5. 总结
每个工具都有其特点,s3cmd功能全面,适合需要细粒度操作的用户,但性能相对较中规中矩;s4cmd基于 s3cmd 增强了速度,适合需要大量并发操作和大文件传输的场景;AWS CLI官方工具,支持所有 AWS 服务的管理,适合需要多种 AWS 服务集成的场景;goofys以本地挂载方式提供灵活性,适合希望将 S3 当作本地磁盘使用的用户;s5cmd以高性能为核心设计,适合对速度有极高需求的数据密集型任务。
对于我来说,主要就是极少数的图片同步到本地,需求场景很简单,怎么方便怎么来,所以用 s3cmd 就能满足,具体怎么选还是要看具体的业务场景。
我的博客即将同步至腾讯云开发者社区,邀请大家一同入驻:https://cloud.tencent.com/developer/support-plan?invite_code=1gih9vl5y1mrs


评论区