

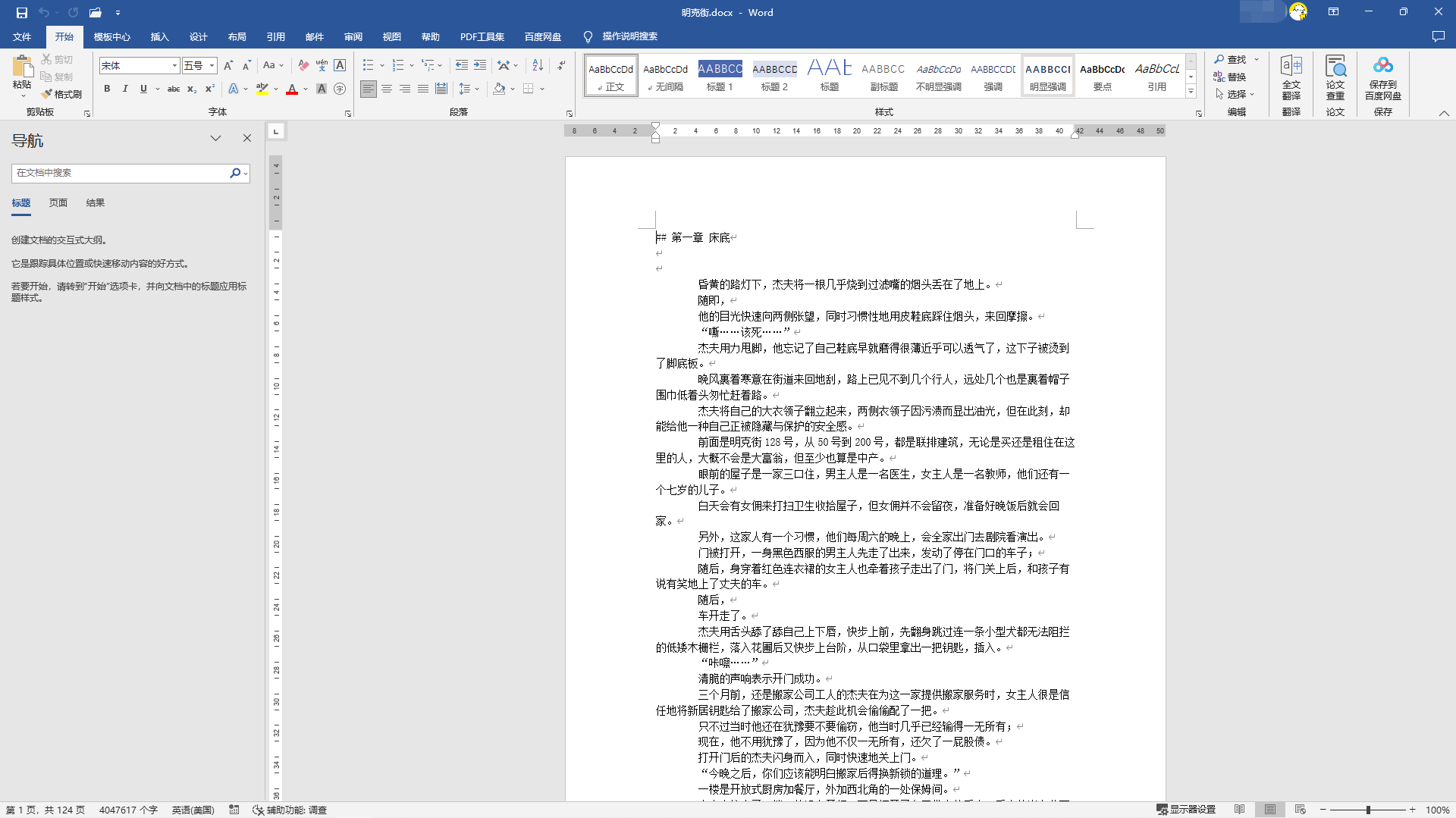
喜欢看小说?上班摸鱼不敢明目张胆的看?看小说还要充钱?这年头,不存在的!从网络上扒数据,写到word文档,免费还能掩人耳目,美哉!美哉!
- 先看效果
目标网站结构分析
目标网站就是我们知名的笔趣阁:https://www.biquzw.la/,知名的搬运网站,受众很大,书源也是海量的,主要是没限制的话,好爬!
开头提到的充钱,主要也是搬运工的功劳,与我无关啊。
-
进入首页,选择我们要爬取的书籍,点进去,刷新页面,确定书籍的url。这里我们可以确定本网站每本书的url是固定的;
-
小说概览页
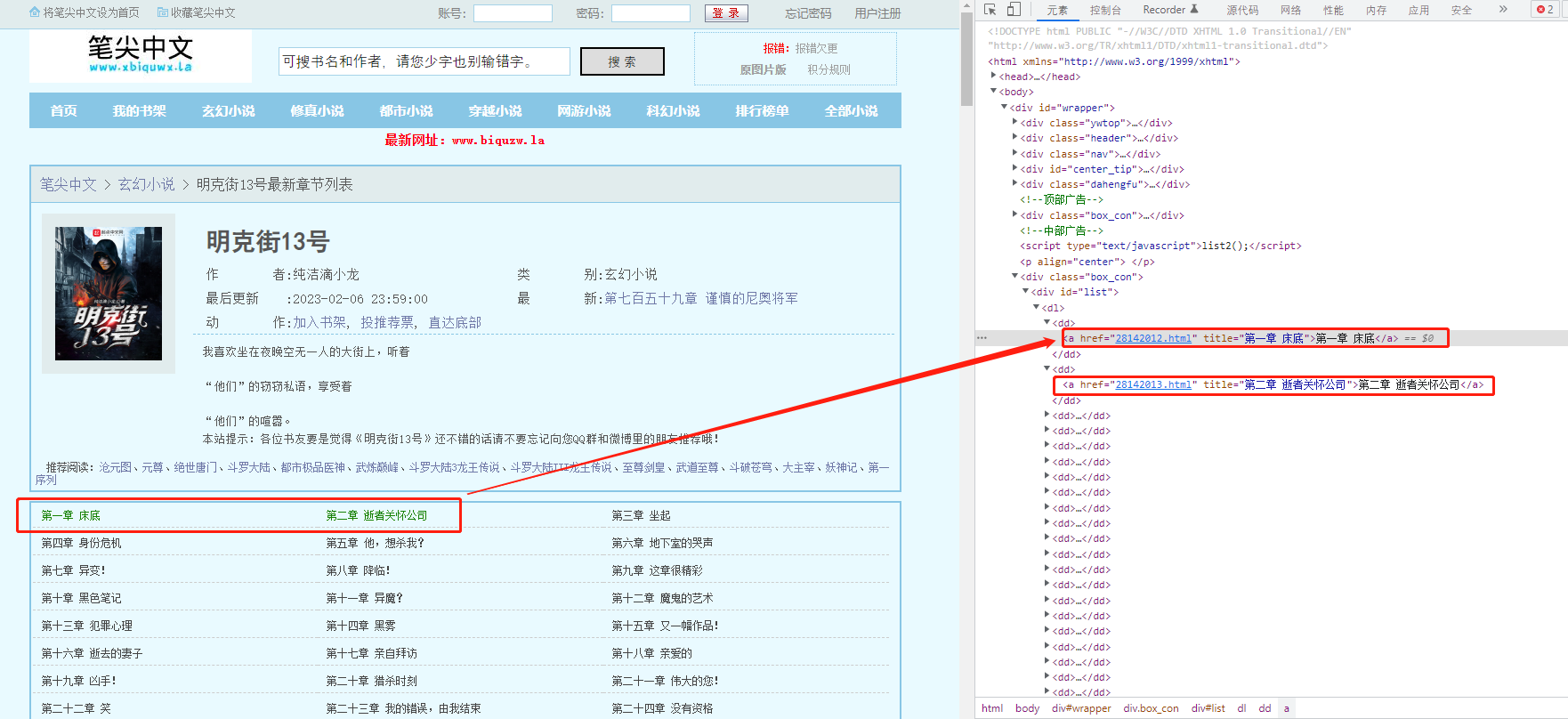
小说详情页,主要是两个部分,一部分是上面的书名、作者、类别等详情信息,另外一部分就是下面的章节信息了;
进一步确认,章节信息全部加载并渲染,所以不用担心获取章节信息的时候还有翻页了。
这里我们还能发现章节相关标签内,还带有一个a标签,点击我们就能发现是对应章的小说内容页。基本可以确定后面获取正文的思路就是获取这个url,进入小说内容页获取正文。
-
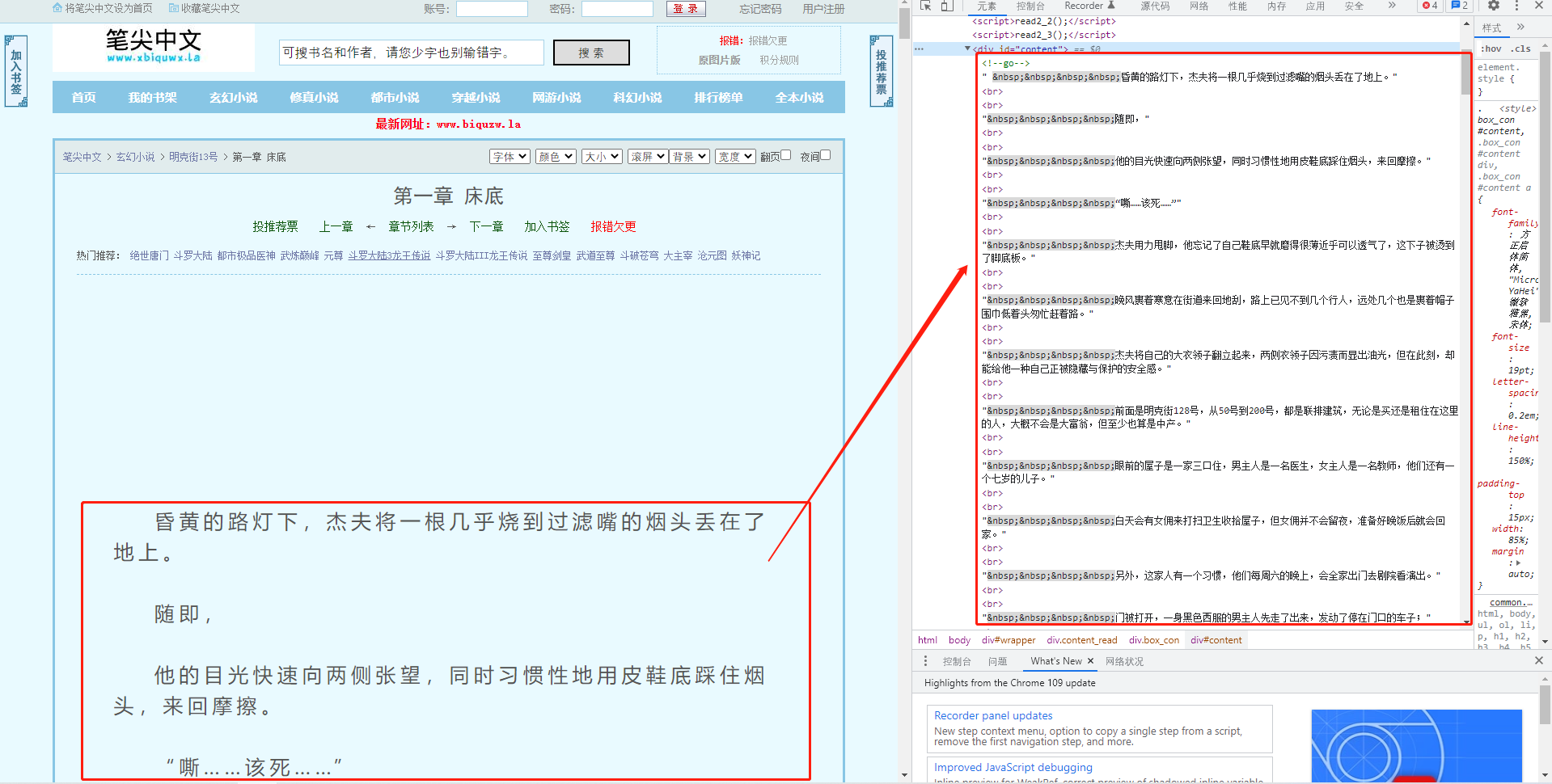
小说阅读页
小说阅读页,也就是小说的正文内容了,正文内容全部在同一个标签内,所以获取方式也很简单,同时结合上面部分,每个章节的url获取也是非常简单的。
至此,基本就可以确定思路了: 手动获取小说url——>爬取章节名称及其url——>正文获取
环境准备
环境还是比较简单的,请求工具+解析工具+文档写入工具,具体包含四个
pip install requests
pip install lxml
pip install docx
# docx包的运行需要依赖python-docx,所以也要安装
pip install python-docx
章节与url获取
请求数据
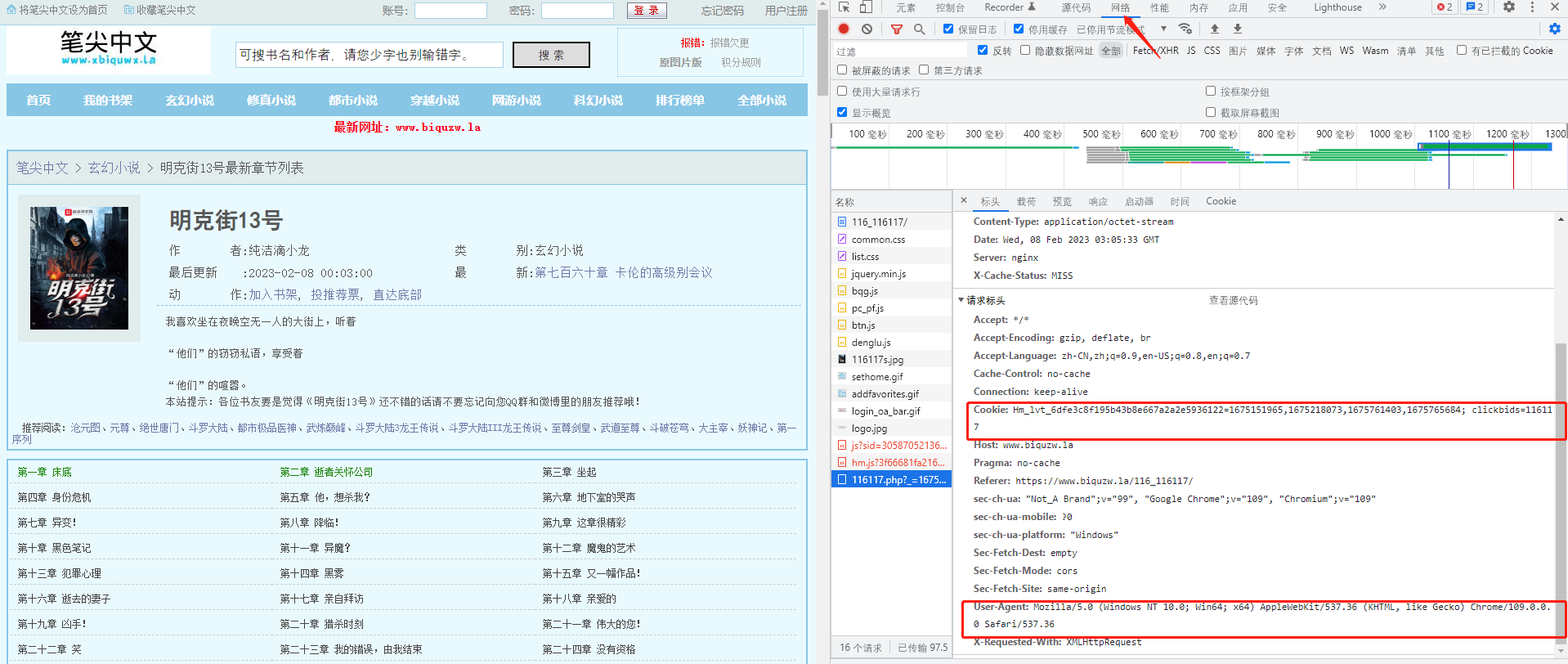
请求网页数据就比较简单,python有很多相关的包,这里就使用requests包就行;另外这种小网站,正常是没有发爬虫机制的,但是为了严谨一点,还是设置一下请求头数据。主要包含cookie和user-agent两个参数。
cookie和user-agent获取方式:
发送请求获取数据
导入requests包,设置headers字典类型的参数,headers就是上面获取的cookie和user-agent参数;然后设置要爬取的小说的url。
以上就完成了基本的参数设置;
数据的请求,一行代码就完成了,即利用requests下的get方法进行请求即可,将请求结果赋值给response;
至此就完成了网页数据的请求;
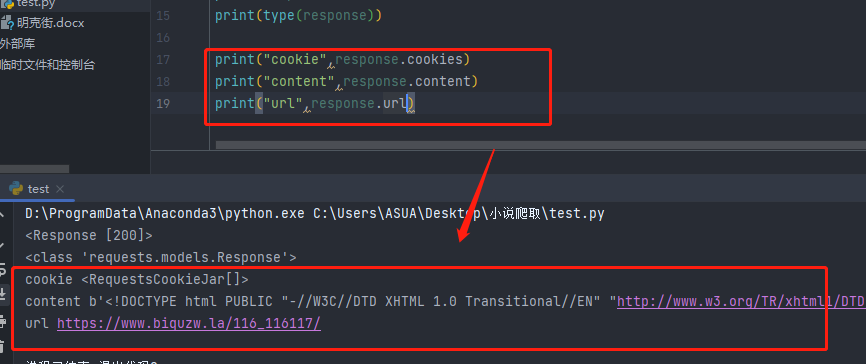
将得到的结果response及其类型打印出来,结果如下;
import requests
headers = {
'Cookie': 'clickbids=116117; Hm_lvt_6dfe3c8f195b43b8e667a2a2e5936122=1675151965,1675218073; Hm_lpvt_6dfe3c8f195b43b8e667a2a2e5936122=1675218073',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
cata_url = 'https://www.biquzw.la/116_116117/'
response = requests.get(cata_url, headers=headers)
print(response)
print(type(response))
# 输出:
# <Response [200]>
# <class 'requests.models.Response'>
解析requests对象
可以很清晰的看到上面获得的数据为一个requests.models.Response对象,进一步要使用这个对象,就需要进行相关的处理;
Response响应的常用属性
response.text # 响应回去的文本(字符串)
response.content # 响应回去的内容(二进制),一般用来爬取视频
response.status_code # 响应的状态码
response.url # 获取请求连接地址
response.cookies # 获取返回的cookies信息
response.cookies.get_dict() # 获取返回的cookies信息
response.request # 获取请求方式
response.json() # 将结果进行反序列化
response.apparent_encoding # 文档的编码的方式(从HTML文档找)
response.encoding # 响应体编码方式
eg: response.encoding = response.apparent_encoding # 文档的声明方式
response.headers # 查看响应头
response.history # 重定向历史 即前一次请求的地址
例:
获取网页数据
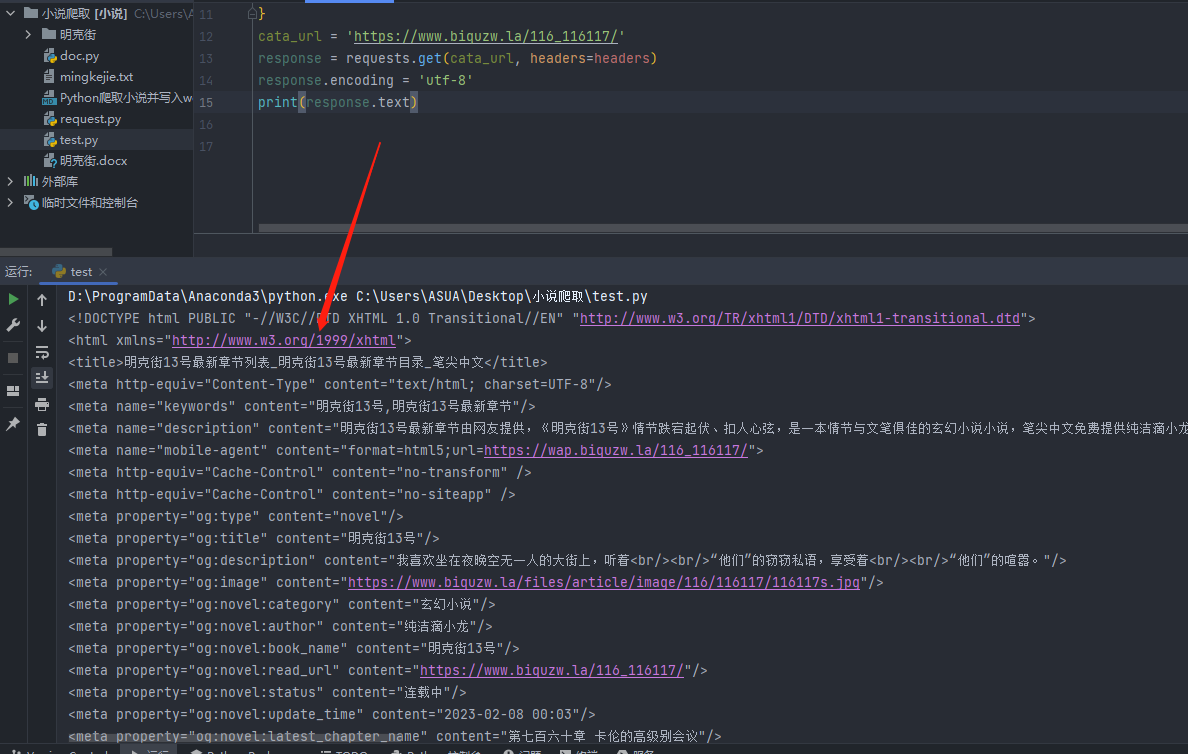
我们要的东西简单直接,就是网页原始文件数据,通过上面这部分的方法,我们直接通过response.text即可获取到网页数据;
但是我们直接打印会发现一个问题,那就是中文乱码;
所以还需要设定一下编码方式response.encoding = 'utf-8';
效果如下,就在第一部分的代码基础上加了两行,就不贴代码了;
提取数据
上面的步骤都还是非常简单的内容,爬虫最麻烦的工作之一就是这里了;
获取到网页数据了,从网页中提取数据的方式很多,常见的有xpath、正则表达式、beautifulsoup等;
具体的还得根据网页的结构来,我们的目标网站结构简单,所以我们直接通过xpath进行获取即可(具体的方式方法后面出文章吧);
要利用xpath解析的话,就需要把网页文本转为html对象;
主要利用的是lxml包;
html = etree.HTML(response.text, parser=etree.HTMLParser(encoding='utf-8'))
i = 1
while True:
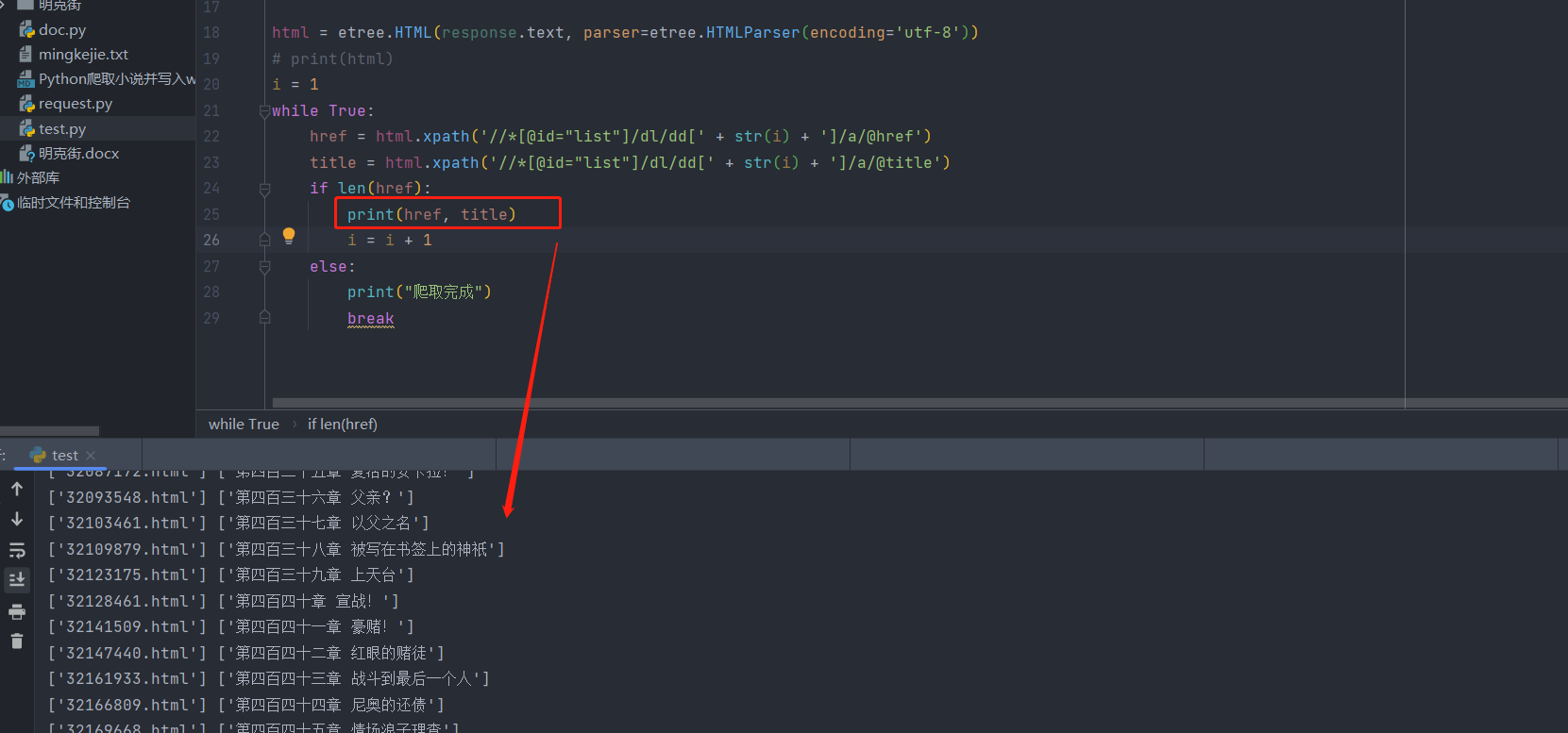
href = html.xpath('//*[@id="list"]/dl/dd[' + str(i) + ']/a/@href')
title = html.xpath('//*[@id="list"]/dl/dd[' + str(i) + ']/a/@title')
if len(href):
print(href, title)
i = i + 1
else:
print("爬取完成")
break
代码也很简单;
首先是转为html对象:
html = etree.HTML(response.text, parser=etree.HTMLParser(encoding='utf-8'))循环获取对应的文字和url:
href = html.xpath('//*[@id="list"]/dl/dd[' + str(i) + ']/a/@href') title = html.xpath('//*[@id="list"]/dl/dd[' + str(i) + ']/a/@title')判断是否正常提取到了文字及url,如果正常就打印并继续循环提取,为空则获取完毕:
if len(href): print(href, title) i = i + 1 content_get(title[0],href[0]) else: print("爬取完成") break
小说内容获取
上面获取到了每个章节的url和标题;
接下来就直接拼接url并获取数据即可;
方法和获取章节信息是相同的,利用requests包请求以及xpath解析即可;
为了配合上面的循环,这里我们将内容获取定义为一个函数:
def content_get(title,url):
content_url = 'https://www.biquzw.la/116_116117/'
content_response = requests.get(content_url + url, headers=headers)
content_response.encoding = 'utf-8'
html = etree.HTML(content_response.text,parser=etree.HTMLParser(encoding='utf-8'))
content = html.xpath('//*[@id="content"]/text()')
for i in range(len(content)):
print(content[i])
在章节获取的循环中调用这个函数即可:content_get(title[0], href[0]);
运行效果:

写入txt/word文档
写入txt
文本数据一般爬取的话就是写入txt文档,如果有特别的需求也可以写入数据库中去;这里主要记录一下写入的思路和方法;主要写入可以分为两个方式,一个就是全部写入同一个文档,另一个是分章节写入不同的txt,同最开始的效果展示一样。
全部写入一个文档就是在爬虫开始的时候就打开一个文档,在爬虫结束的时候才关闭这个文档;分别写入不同的文档的话,就需要不断的新建文档;
所以二者的代码结构是不同的,但是方法相同,几行代码就能达到我们的目标;
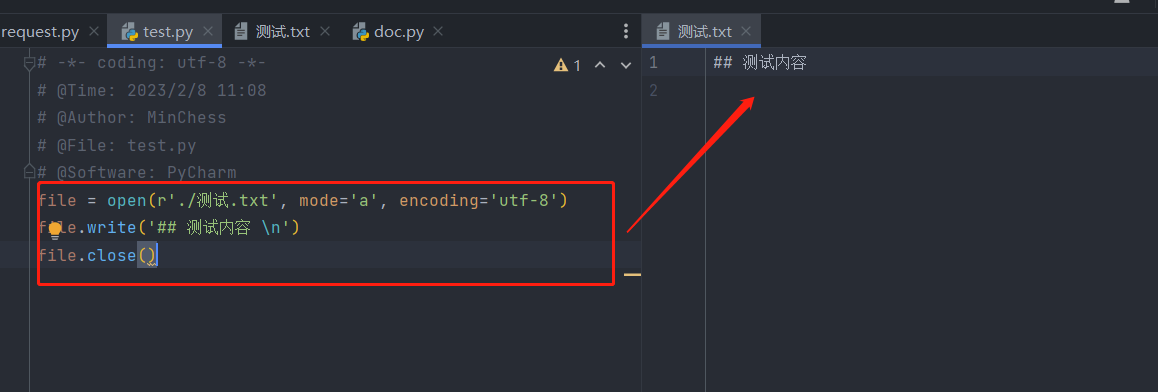
file = open(r'./测试.txt', mode='a', encoding='utf-8')
file.write('## 测试内容 \n')
file.close()
效果如下:
具体在本应用中的结构参看完整代码
写入word
写入word的思路同样很简单,将标题设置为标题,将文本内容设置为正文;
所以我们知道怎么向word写入标题和正文即可,不需要写入图片以及设置样式啥的,所以还是比较简单的,当然这些也能实现,但是这里没必要么;
# -*- coding: utf-8 -*-
# @Time: 2023/2/1 11:49
# @Author: MinChess
# @File: doc.py
# @Software: PyCharm
import docx
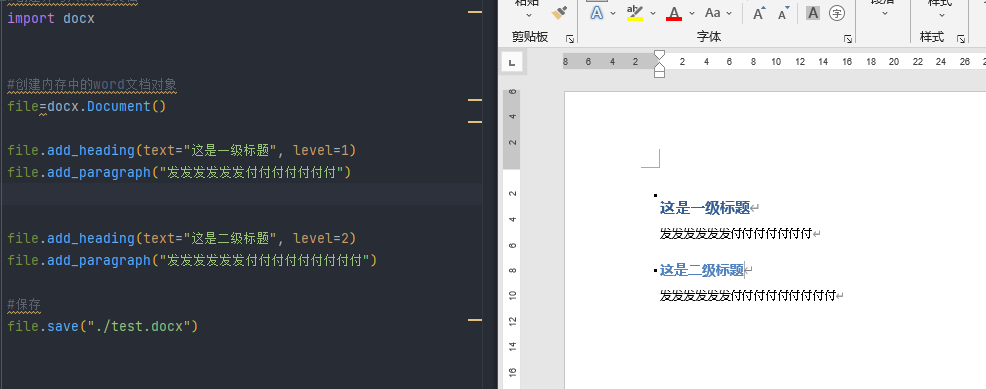
#创建内存中的word文档对象
file=docx.Document()
file.add_heading(text="这是一级标题", level=1)
file.add_paragraph("发发发发发发付付付付付付付")
file.add_heading(text="这是二级标题", level=2)
file.add_paragraph("发发发发发发付付付付付付付付付")
#保存
file.save("./test.docx")
方法也很简单,利用docx包对应的方法即可,效果如下:
具体的使用参看完整代码,但是这个代码还是不太好,太乱了,大家可以多去琢磨琢磨,优化优化;

完整代码
- 分别写入txt文档:
# -*- coding: utf-8 -*-
# @Time: 2023/2/1 10:29
# @Author: MinChess
# @File: request.py
# @Software: PyCharm
import requests
from lxml import etree
headers = {
'Cookie': 'clickbids=116117; Hm_lvt_6dfe3c8f195b43b8e667a2a2e5936122=1675151965,1675218073; Hm_lpvt_6dfe3c8f195b43b8e667a2a2e5936122=1675218073',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
def catalog_get():
cata_url = 'https://www.biquzw.la/116_116117/'
response = requests.get(cata_url, headers=headers)
response.encoding = 'utf-8'
# print(response.text)
html = etree.HTML(response.text, parser=etree.HTMLParser(encoding='utf-8'))
# print(html)
i = 1
while True:
href = html.xpath('//*[@id="list"]/dl/dd[' + str(i) + ']/a/@href')
title = html.xpath('//*[@id="list"]/dl/dd[' + str(i) + ']/a/@title')
if len(href):
print(href, title)
i = i + 1
content_get(title[0],href[0])
else:
print("爬取完成")
break
def content_get(title,url):
file = open(r'./明克街/'+title+'.txt', mode='a', encoding='utf-8')
file.write('## ' + title + '\n')
content_url = 'https://www.biquzw.la/116_116117/'
content_response = requests.get(content_url + url, headers=headers)
content_response.encoding = 'utf-8'
# print(content_response.text)
html = etree.HTML(content_response.text,parser=etree.HTMLParser(encoding='utf-8'))
content = html.xpath('//*[@id="content"]/text()')
# a_res = etree.tostring(content[0], encoding='utf-8').strip().decode('utf-8')
# print(a_res)
# print(content)
for i in range(len(content)):
# print(content[i])
file.write(content[i]+'\n')
file.close()
if __name__ == '__main__':
catalog_get()
- 写入word文档
# -*- coding: utf-8 -*-
# @Time: 2023/2/8 17:47
# @Author: MinChess
# @File: reword.py
# @Software: PyCharm
import requests
from lxml import etree
import docx
headers = {
'Cookie': 'clickbids=116117; Hm_lvt_6dfe3c8f195b43b8e667a2a2e5936122=1675151965,1675218073; Hm_lpvt_6dfe3c8f195b43b8e667a2a2e5936122=1675218073',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
file = docx.Document()
def catalog_get():
cata_url = 'https://www.biquzw.la/116_116117/'
response = requests.get(cata_url, headers=headers)
response.encoding = 'utf-8'
html = etree.HTML(response.text, parser=etree.HTMLParser(encoding='utf-8'))
i = 1
while True:
href = html.xpath('//*[@id="list"]/dl/dd[' + str(i) + ']/a/@href')
title = html.xpath('//*[@id="list"]/dl/dd[' + str(i) + ']/a/@title')
if len(href):
print(href, title)
i = i + 1
content_get(title[0],href[0])
else:
print("爬取完成")
file.save("./mkj.docx")
break
def content_get(title,url):
file.add_heading(text=title, level=1)
content_url = 'https://www.biquzw.la/116_116117/'
content_response = requests.get(content_url + url, headers=headers)
content_response.encoding = 'utf-8'
html = etree.HTML(content_response.text,parser=etree.HTMLParser(encoding='utf-8'))
content = html.xpath('//*[@id="content"]/text()')
for i in range(len(content)):
# print(content[i])
file.add_paragraph(content[i])
if __name__ == '__main__':
catalog_get()
总结
环境没问题的话,代码应该是可以直接跑的,思路还是比较清晰的;
先分析网站结构,其次是小说章节信息的获取,再是小说内容的获取,清晰简单;
批量爬取小说思路
这个就简单的扩展一下,我们发现网站中会有一个全部小说页,内容就是小说列表;
所以思路就是爬取这个页面的小说名称和基本信息以及小说概览页的URL;
进一步重复本文的主要工作就行;
可能稍微麻烦点的就是如何翻页,两种方式,一个是直接获取URL,另一个就是根据URL规律拼接URL;两种方式需要根据实际情况来看;
思路就是这样了,也比较简单,快去敲代码试试!!!



评论区