

前面了解了一下python的类型提示,这里就接着记录一下Pydantic这个用来执行数据校验的库。而且FastAPI就是基于python的类型提示和Padantic实现的数据验证。
简介
-
Pydantic就是一个基于Python类型提示来定义数据验证、序列化和文档(使用JSON模式)的库;
-
使用Python的类型提示来进行数据校验和settings管理;
-
可以在代码运行的时候提供类型提示,数据校验失败的时候提供友好的错误提示;
-
定义数据应该如何在纯规范的Python代码中保存,并用Pydantic验证;
基本用法
-
数据规范的情况
这里的
**符号是为了分配参数用的,可以分配字典
# -*- coding: utf-8 -*-
# @Time: 2022/11/23 15:42
# @Author: MinChess
# @File: pydantic_tutorial.py
# @Software: PyCharm
from pydantic import BaseModel
from datetime import datetime
from typing import List,Optional
class User(BaseModel):
id: int #必填字段(无默认值的时候,其为必填字段)
name: str = "MinChess" #有默认值,选填字段
signup_ts: Optional[datetime] = None
friends: List[int] = [] # 列表中的元素需要是int类型或者能转换为int类型的str
external_data = {
"id":"123",
"signuo_ts": "2011-2-12 12:23:20",
"friends": [1,2,'3']
}
user = User(**external_data)
print(user.id,user.friends)
print(repr(user.signup_ts))
print(user.dict())
运行结果:
123 [1, 2, 3]
None
{'id': 123, 'name': 'MinChess', 'signup_ts': None, 'friends': [1, 2, 3]}
字符串类型的数据也转为了int型
- 数据不规范:id不为int类型或可转为int的str类型
external_data = {
"id":"123h",
"signuo_ts": "2011-2-12 12:23:20",
"friends": [1,2,'3']
}
输出:
Traceback (most recent call last):
File "E:\project\PythonProject\FastApiProject\pydantic_tutorial.py", line 23, in <module>
user = User(**external_data)
File "pydantic\main.py", line 342, in pydantic.main.BaseModel.__init__
pydantic.error_wrappers.ValidationError: 1 validation error for User
id
value is not a valid integer (type=type_error.integer)
报错说id是int型,这里就可以看出,提示和规范还是非常友好的了
校验失败处理
- 给属性赋错误类型
try:
User(id=1,signup_ts=datetime.now(),friends=[1,5,'dsd']) # 直接给属性赋值
except ValidationError as e:
print(e.json()) # 错误json格式化
- 输出结果:
[
{
"loc": [
"friends",
2
],
"msg": "value is not a valid integer",
"type": "type_error.integer"
}
]
模型类的属性和方法
- 解析和转换
print(user.dict()) # 转换为字典
print(user.json()) # 转换为json
print(user.copy()) # 浅copy
print(User.parse_obj(obj=external_data)) # 直接解析字典数据
print(User.parse_raw('{"id": 123, "name": "MinChess", "signup_ts": null, "friends": [1, 2, 3]}')) # 解析标准格式的数据,里面是双引号
path = Path('pydantic_tutorial.json')
path.write_text('{"id": 123, "name": "MinChess", "signup_ts": null, "friends": [1, 2, 3]}')
print(User.parse_file(path)) # 解析文件
print(user.schema()) #此方法用来告诉我们实例的数据格式的方案
print(user.schema_json())
user_data = {"id": 123, "name": "MinChess", "signup_ts": "2022-12-20 12:12:30", "friends": [1, 2, 3]}
print(User.construct(**user_data)) # 此方法不校验数据,直接创建模型类
print(User.__fields__.keys()) # (这里查看所有字段)定义模型类的时候,所有字段都注明类型,字段顺序就不会乱
- 输出:
{'id': 123, 'name': 'MinChess', 'signup_ts': None, 'friends': [1, 2, 3]}
{"id": 123, "name": "MinChess", "signup_ts": null, "friends": [1, 2, 3]}
id=123 name='MinChess' signup_ts=None friends=[1, 2, 3]
id=123 name='MinChess' signup_ts=None friends=[1, 2, 3]
id=123 name='MinChess' signup_ts=None friends=[1, 2, 3]
id=123 name='MinChess' signup_ts=None friends=[1, 2, 3]
{'title': 'User', 'type': 'object', 'properties': {'id': {'title': 'Id', 'type': 'integer'}, 'name': {'title': 'Name', 'default': 'MinChess', 'type': 'string'}, 'signup_ts': {'title': 'Signup Ts', 'type': 'string', 'format': 'date-time'}, 'friends': {'title': 'Friends', 'default': [], 'type': 'array', 'items': {'type': 'integer'}}}, 'required': ['id']}
{"title": "User", "type": "object", "properties": {"id": {"title": "Id", "type": "integer"}, "name": {"title": "Name", "default": "MinChess", "type": "string"}, "signup_ts": {"title": "Signup Ts", "type": "string", "format": "date-time"}, "friends": {"title": "Friends", "default": [], "type": "array", "items": {"type": "integer"}}}, "required": ["id"]}
id=123 name='MinChess' signup_ts='2022-12-20 12:12:30' friends=[1, 2, 3]
dict_keys(['id', 'name', 'signup_ts', 'friends'])
递归模型
- 创建递归
class Sound(BaseModel):
sound:str
class Dog(BaseModel):
birthday: date
weight: float = Optional[None]
sound: List[Sound]
dogs = Dog(birthday=date.today(),weight=6.25,sound=[{"sound":"wang wang"},{"sound":"ying ying"}])
print(dogs.json())
- 输出
{"birthday": "2022-11-23", "sound": [{"sound": "wang wang"}, {"sound": "ying ying"}]}
ORM模型
ORM 全称 Object Relational Mapping, 叫对象关系映射。简单的说,ORM 将数据库中的表与面向对象语言中的类建立了一种对应关系。
- 利用
sqlalchemy创建模型
Base = declarative_base()
class CompanyOrm(Base):
__tablename__ = 'companies'
id = Column(Integer,primary_key = True,nullable = False)
public_key = Column(String(20),index = True,nullable = False ,unique = True)
name = Column(String(63),unique=True)
domains = Column(ARRAY(String(255)))
class CompanyModel(BaseModel):
id:int
public_key:constr(max_length=20)
name:constr(max_length=63)
domains:List[constr(max_length=255)]
class Config:
orm_mode = True
co_orm = CompanyOrm(
id = 12,
public_key= 'dddddd',
name= 'MinChess',
domains=['eeeeeee','fffffff']
)
print(CompanyModel.from_orm(co_orm))
- 输出
id=12 public_key='dddddd' name='MinChess' domains=['eeeeeee', 'fffffff']
Pydantic支持的所有字段类型
Pydantic支持很多类型的数据,除了常用的那些基本类型外,还有一些不常用的类型,具体参看官网:
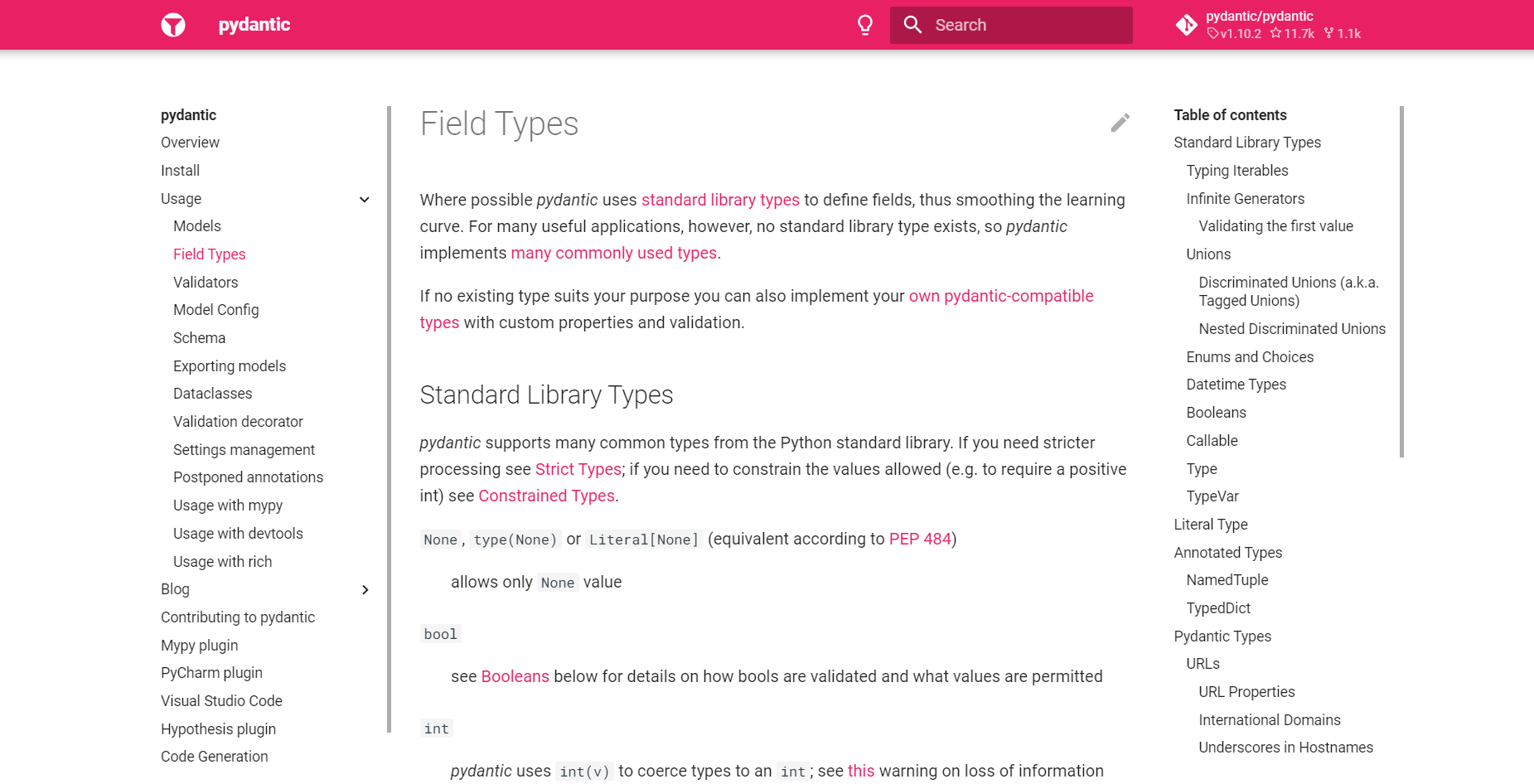
源码
# -*- coding: utf-8 -*-
# @Time: 2022/11/23 15:42
# @Author: MinChess
# @File: pydantic_tutorial.py
# @Software: PyCharm
from pydantic import BaseModel,ValidationError,constr
from datetime import datetime,date
from pathlib import Path
from typing import List,Optional
from sqlalchemy import Column,Integer,String
from sqlalchemy.dialects.postgresql import ARRAY
from sqlalchemy.ext.declarative import declarative_base
class User(BaseModel):
id: int #必填字段(无默认值的时候,其为必填字段)
name: str = "MinChess" #有默认值,选填字段
signup_ts: Optional[datetime] = None
friends: List[int] = [] # 列表中的元素需要是int类型或者能转换为int类型的str
external_data = {
"id":"123",
"signuo_ts": "2011-2-12 12:23:20",
"friends": [1,2,'3']
}
user = User(**external_data)
print("====="*6,'基本使用','====='*6)
print(user.id,user.friends)
print(repr(user.signup_ts))
print(user.dict())
print("====="*6,'校验失败处理','====='*6)
try:
User(id=1,signup_ts=datetime.now(),friends=[1,5,'dsd']) # 直接给属性赋值
except ValidationError as e:
print(e.json()) # 错误json格式化
print("====="*6,'模型类的属性和方法','====='*6)
print(user.dict()) # 转换为字典
print(user.json()) # 转换为json
print(user.copy()) # 浅copy
print(User.parse_obj(obj=external_data)) # 直接解析字典数据
print(User.parse_raw('{"id": 123, "name": "MinChess", "signup_ts": null, "friends": [1, 2, 3]}')) # 解析标准格式的数据,里面是双引号
path = Path('pydantic_tutorial.json')
path.write_text('{"id": 123, "name": "MinChess", "signup_ts": null, "friends": [1, 2, 3]}')
print(User.parse_file(path)) # 解析文件
print(user.schema()) #此方法用来告诉我们实例的数据格式的方案
print(user.schema_json())
user_data = {"id": 123, "name": "MinChess", "signup_ts": "2022-12-20 12:12:30", "friends": [1, 2, 3]}
print(User.construct(**user_data)) # 此方法不校验数据,直接创建模型类
print(User.__fields__.keys()) # (这里查看所有字段)定义模型类的时候,所有字段都注明类型,字段顺序就不会乱
print("====="*6,'递归模型','====='*6)
class Sound(BaseModel):
sound:str
class Dog(BaseModel):
birthday: date
weight: float = Optional[None]
sound: List[Sound]
dogs = Dog(birthday=date.today(),weight=6.25,sound=[{"sound":"wang wang"},{"sound":"ying ying"}])
print(dogs.json())
print("====="*6,'ORM模型','====='*6)
Base = declarative_base()
class CompanyOrm(Base):
__tablename__ = 'companies'
id = Column(Integer,primary_key = True,nullable = False)
public_key = Column(String(20),index = True,nullable = False ,unique = True)
name = Column(String(63),unique=True)
domains = Column(ARRAY(String(255)))
class CompanyModel(BaseModel):
id:int
public_key:constr(max_length=20)
name:constr(max_length=63)
domains:List[constr(max_length=255)]
class Config:
orm_mode = True
co_orm = CompanyOrm(
id = 12,
public_key= 'dddddd',
name= 'MinChess',
domains=['eeeeeee','fffffff']
)
print(CompanyModel.from_orm(co_orm))


评论区