

词频统计
TF-IDF和词频是脱不了关系的,所以在这里再记录一下关于词频的内容。
其实在词云图那块儿就已经完成了词频统计,这里记录另一种方法,即利用NLTK包实现统计与可视化。
- 完整代码(不能直接使用,需要jieba分词中清洗后分词并停用词中的方法)
# -*- coding: utf-8 -*-
# @Time : 2022/5/1 17:07
# @Author : MinChess
# @File : test5.py
# @Software: PyCharm
from nltk import *
from StopWords import readFile,seg_doc #这里是基于jieba分词中的方法
import matplotlib
# 设置使用字体
matplotlib.rcParams['font.sans-serif'] = 'SimHei'
# 利用nltk进行词频特征统计
def nltk_wf_feature(word_list=None):
fdist=FreqDist(word_list)
print(fdist.keys(),fdist.values())
print('='*3,'指定词语词频统计','='*3)
w='关键词'
print(w,'出现频率:',fdist.freq(w)) # 给定样本的频率
print(w,'出现次数:',fdist[w]) # 出现次数
print('='*3,'频率分布表','='*3)
fdist.tabulate(10) # 频率分布表(前n个词)
# 可视化
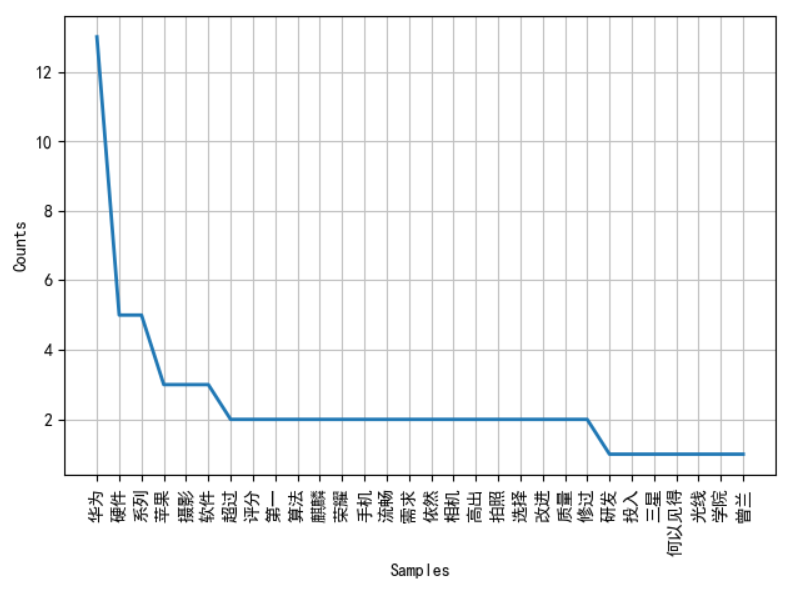
fdist.plot(30) # 频率分布图
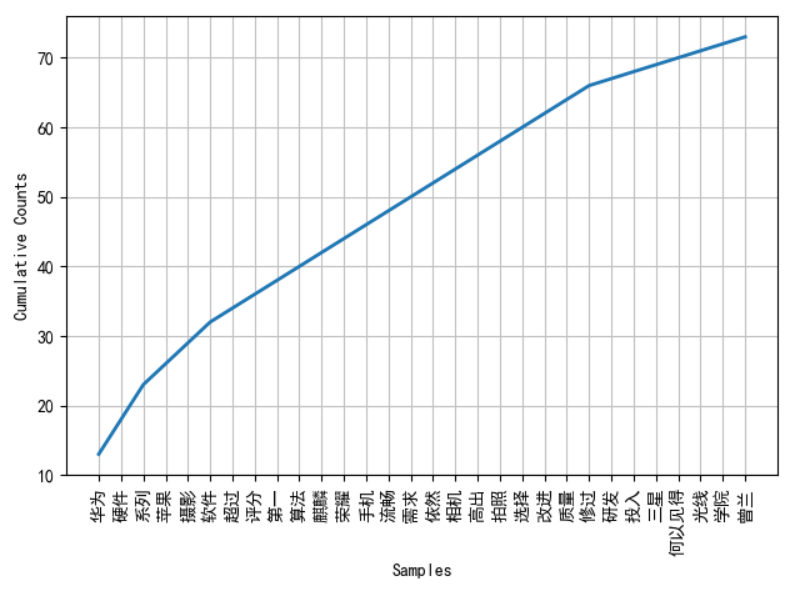
fdist.plot(30,cumulative=True) # 频率累计图
print('='*3,'根据词语长度查找词语','='*3)
wlist =[w for w in fdist if len(w)>2]
print(wlist)
return fdist
if __name__=='__main__':
path= r'xxxx.txt'
str_doc = readFile(path)
# print(str_doc)
# 2 词频特征统计
word_list =seg_doc(str_doc)
fdist = nltk_wf_feature(word_list)
- 输出结果,分别对应频率分布图与频率累计图
TF-IDF计算
TF-IDF (Term Frequency-nversDocument Frequency)是一种常用于信息处理和数据挖掘的加权技术。该技术采用一种统计方法,根据字词的在文本中出现的次数和在整个语料中出现的文档频率来计算一个字词在整个语料中的重要程度。它的优点是能过滤掉一些常见的却无关紧要本的词语,同时保留影响整个文本的重要字词。计算方法如下面公式所示:
TF (Term Frequency)为某个关键词在整篇文章中出现的频率。IDF (InversDocument Frequency)计算倒文本率。文本频率是指某个关键词在整个语料所有文章中出现的次数。倒文档频率又称为逆文档频率,它是文档频率的倒数,主要用于降低所有文档中一些常见却对文档影响不大的词语的作用。
TF-IDF统计可视化的完整代码:
# -*- coding: utf-8 -*-
# @Time : 2022/5/1 16:55
# @Author : MinChess
# @File : tfidf.py
# @Software: PyCharm
import os
import time
import pandas as pd
import numpy as np
import jieba
import jieba.analyse
import matplotlib.pyplot as plt
from PIL import Image
from datetime import datetime
from matplotlib.font_manager import FontProperties
cut_words = ""
for line in open('待处理.txt', encoding='utf-8'):
line.strip('\n')
seg_list = jieba.cut(line,cut_all=False)
cut_words += (" ".join(seg_list))
# jieba.load_userdict("userdict.txt")
# jieba.analyse.set_stop_words('stop_words.txt')
# 提取主题词 返回的词频其实就是TF-IDF
keywords = jieba.analyse.extract_tags(cut_words,
topK=50,
withWeight=True,
allowPOS=('a','e','n','nr','ns', 'v'))
# 以列表形式返回
print(keywords)
# 数据存储
pd.DataFrame(keywords, columns=['词语','重要性']).to_excel('关键词前50.xlsx')
# keyword本身包含两列数据
ss = pd.DataFrame(keywords,columns = ['词语','重要性'])
# print(ss)
# 可视化
plt.figure(figsize=(10,6))
plt.title('TF-IDF Ranking')
fig = plt.axes()
plt.barh(range(len(ss.重要性[:25][::-1])),ss.重要性[:25][::-1])
fig.set_yticks(np.arange(len(ss.重要性[:25][::-1])))
font = FontProperties(fname=r'simsun.ttc')
fig.set_yticklabels(ss.词语[:25][::-1],fontproperties=font)
fig.set_xlabel('Importance')
plt.show()
TF-IDF还有很对方面值得探索,绝不仅上述的内容而已。后续还会不断完善


评论区